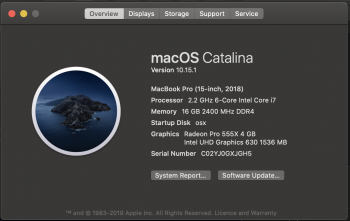
The MacBook Pro 2018 has two GPUs:
AMD Radeon Pro 555X and Intel(R) UHD Graphics 630.
I supposed the AMD 555X would be superior in performance compared to the Intel(R) UHD Graphics 630.
However, I observed a huge performance difference for Metal Performance Shaders (MPS) between the two GPUs.
The Intel GPU performs the simple test code (a MPSMatrixMultiplication) 3 times faster compared to the AMD 555X.
You can compile the attached code in a Terminal by 'swiftc -O matrixMul.swift'
and run it by executing './matrixMul'
In the test code, I can select execution on the AMD 555X with the statement
let device = devices[0] // AMD Radeon Pro 555X
and I get the following:
start calculation on GPU-device <BronzeMtlDevice: 0x1071bf000>
name = AMD Radeon Pro 555X
...
GPU execution time = 12.612 seconds
The Intel(R) UHD Graphics 630 is selected by
let device = devices[1] // Intel(R) UHD Graphics 630
and I get
start calculation on GPU-device <MTLIGAccelDevice: 0x10f9c5000>
name = Intel(R) UHD Graphics 630
...
GPU execution time = 3.735 seconds
As you can see the Intel UHD 630 performed the MPSMatrixMultiplication 3 times faster than the AMD 555X.
I thought the AMD 555X would be more powerful than the Intel UHD 630, but this test shows the opposite.
I wonder why? Any idea?
-------------------- test code
import Metal
import Accelerate
import MetalPerformanceShaders
let devices = MTLCopyAllDevices()
print("available GPUs")
for d in devices {
print(d)
}
// select one of the two GPS by commenting out one of the two
let device = devices[0] // AMD Radeon Pro 555X
//let device = devices[1] // Intel(R) UHD Graphics 630
// commandQueue and commandBuffer
let commandQueue = device.makeCommandQueue()!;
let commandBuffer = commandQueue.makeCommandBuffer()!;
// Matrix dimensions
let n = 8192 // matrix dimension (n x n)
let rowsA = n
let columnsA = n
let rowsB = n
let columnsB = n
let rowsC = n
let columnsC = n
// matrix A data
var arrayA = [Float](repeating: 0, count: rowsA * columnsA)
for i in 0..<arrayA.count { // set random data
arrayA = Float(2 * drand48() - 1)
}
// matrix B data
var arrayB = [Float](repeating: 0, count: rowsB * columnsB)
for i in 0..<arrayB.count { // set random data
arrayB = Float(2 * drand48() - 1)
}
// MTL data buffers for Matrices A,B,C
let bufferA = device.makeBuffer(bytes: arrayA,
length: rowsA * columnsA * MemoryLayout<Float>.stride,
options: [])!;
let bufferB = device.makeBuffer(bytes: arrayB,
length: rowsB * columnsB * MemoryLayout<Float>.stride,
options: [])!;
let bufferC = device.makeBuffer(length: rowsC * columnsC * MemoryLayout<Float>.stride,
options: [])!;
// Matrix descriptions
let descA = MPSMatrixDescriptor(dimensions: rowsA, columns: columnsA,
rowBytes: columnsA * MemoryLayout<Float>.stride,
dataType: .float32);
let descB = MPSMatrixDescriptor(dimensions: rowsB, columns: columnsB,
rowBytes: columnsB * MemoryLayout<Float>.stride,
dataType: .float32);
let descC = MPSMatrixDescriptor(dimensions: rowsC, columns: columnsC,
rowBytes: columnsC * MemoryLayout<Float>.stride,
dataType: .float32);
// MTL matrix buffers
let matrixA = MPSMatrix(buffer: bufferA, descriptor: descA);
let matrixB = MPSMatrix(buffer: bufferB, descriptor: descB);
let matrixC = MPSMatrix(buffer: bufferC, descriptor: descC);
let matrixMultiplication = MPSMatrixMultiplication(device: device,
transposeLeft: false, transposeRight: false,
resultRows: rowsC, resultColumns: columnsC,
interiorColumns: columnsA, alpha: 1, beta: 0);
matrixMultiplication.encode(commandBuffer: commandBuffer, leftMatrix: matrixA,
rightMatrix: matrixB, resultMatrix: matrixC);
print("start calculation on GPU-device \(device)")
let start = DispatchTime.now().uptimeNanoseconds;
commandBuffer.commit()
commandBuffer.waitUntilCompleted()
let end = DispatchTime.now().uptimeNanoseconds
let execTime = String(format: "%.3f", 1e-9 * Double(end - start))
// we look at the result
let rawPointer = matrixC.data.contents();
let count = matrixC.rows * matrixC.columns;
let typedPointer = rawPointer.bindMemory(to: Float.self, capacity: count);
let bufferedPointer = UnsafeBufferPointer(start: typedPointer, count: count);
// Print the first 10 results, to make sure it's not all 0s or NaNs.
print("\nFirst 5 elements:")
for i in 0..<5 {
print("element \(i) =", bufferedPointer);
}
print("...")
print("last element =", bufferedPointer[n * n - 1]);
print("...")
print("GPU execution time = \(execTime) seconds")
exit(0)
------------------ end test-code
AMD Radeon Pro 555X and Intel(R) UHD Graphics 630.
I supposed the AMD 555X would be superior in performance compared to the Intel(R) UHD Graphics 630.
However, I observed a huge performance difference for Metal Performance Shaders (MPS) between the two GPUs.
The Intel GPU performs the simple test code (a MPSMatrixMultiplication) 3 times faster compared to the AMD 555X.
You can compile the attached code in a Terminal by 'swiftc -O matrixMul.swift'
and run it by executing './matrixMul'
In the test code, I can select execution on the AMD 555X with the statement
let device = devices[0] // AMD Radeon Pro 555X
and I get the following:
start calculation on GPU-device <BronzeMtlDevice: 0x1071bf000>
name = AMD Radeon Pro 555X
...
GPU execution time = 12.612 seconds
The Intel(R) UHD Graphics 630 is selected by
let device = devices[1] // Intel(R) UHD Graphics 630
and I get
start calculation on GPU-device <MTLIGAccelDevice: 0x10f9c5000>
name = Intel(R) UHD Graphics 630
...
GPU execution time = 3.735 seconds
As you can see the Intel UHD 630 performed the MPSMatrixMultiplication 3 times faster than the AMD 555X.
I thought the AMD 555X would be more powerful than the Intel UHD 630, but this test shows the opposite.
I wonder why? Any idea?
-------------------- test code
import Metal
import Accelerate
import MetalPerformanceShaders
let devices = MTLCopyAllDevices()
print("available GPUs")
for d in devices {
print(d)
}
// select one of the two GPS by commenting out one of the two
let device = devices[0] // AMD Radeon Pro 555X
//let device = devices[1] // Intel(R) UHD Graphics 630
// commandQueue and commandBuffer
let commandQueue = device.makeCommandQueue()!;
let commandBuffer = commandQueue.makeCommandBuffer()!;
// Matrix dimensions
let n = 8192 // matrix dimension (n x n)
let rowsA = n
let columnsA = n
let rowsB = n
let columnsB = n
let rowsC = n
let columnsC = n
// matrix A data
var arrayA = [Float](repeating: 0, count: rowsA * columnsA)
for i in 0..<arrayA.count { // set random data
arrayA = Float(2 * drand48() - 1)
}
// matrix B data
var arrayB = [Float](repeating: 0, count: rowsB * columnsB)
for i in 0..<arrayB.count { // set random data
arrayB = Float(2 * drand48() - 1)
}
// MTL data buffers for Matrices A,B,C
let bufferA = device.makeBuffer(bytes: arrayA,
length: rowsA * columnsA * MemoryLayout<Float>.stride,
options: [])!;
let bufferB = device.makeBuffer(bytes: arrayB,
length: rowsB * columnsB * MemoryLayout<Float>.stride,
options: [])!;
let bufferC = device.makeBuffer(length: rowsC * columnsC * MemoryLayout<Float>.stride,
options: [])!;
// Matrix descriptions
let descA = MPSMatrixDescriptor(dimensions: rowsA, columns: columnsA,
rowBytes: columnsA * MemoryLayout<Float>.stride,
dataType: .float32);
let descB = MPSMatrixDescriptor(dimensions: rowsB, columns: columnsB,
rowBytes: columnsB * MemoryLayout<Float>.stride,
dataType: .float32);
let descC = MPSMatrixDescriptor(dimensions: rowsC, columns: columnsC,
rowBytes: columnsC * MemoryLayout<Float>.stride,
dataType: .float32);
// MTL matrix buffers
let matrixA = MPSMatrix(buffer: bufferA, descriptor: descA);
let matrixB = MPSMatrix(buffer: bufferB, descriptor: descB);
let matrixC = MPSMatrix(buffer: bufferC, descriptor: descC);
let matrixMultiplication = MPSMatrixMultiplication(device: device,
transposeLeft: false, transposeRight: false,
resultRows: rowsC, resultColumns: columnsC,
interiorColumns: columnsA, alpha: 1, beta: 0);
matrixMultiplication.encode(commandBuffer: commandBuffer, leftMatrix: matrixA,
rightMatrix: matrixB, resultMatrix: matrixC);
print("start calculation on GPU-device \(device)")
let start = DispatchTime.now().uptimeNanoseconds;
commandBuffer.commit()
commandBuffer.waitUntilCompleted()
let end = DispatchTime.now().uptimeNanoseconds
let execTime = String(format: "%.3f", 1e-9 * Double(end - start))
// we look at the result
let rawPointer = matrixC.data.contents();
let count = matrixC.rows * matrixC.columns;
let typedPointer = rawPointer.bindMemory(to: Float.self, capacity: count);
let bufferedPointer = UnsafeBufferPointer(start: typedPointer, count: count);
// Print the first 10 results, to make sure it's not all 0s or NaNs.
print("\nFirst 5 elements:")
for i in 0..<5 {
print("element \(i) =", bufferedPointer);
}
print("...")
print("last element =", bufferedPointer[n * n - 1]);
print("...")
print("GPU execution time = \(execTime) seconds")
exit(0)
------------------ end test-code