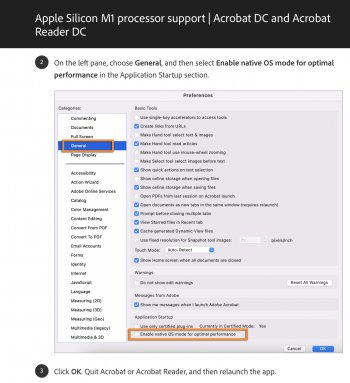
How did this project work out for you in the end?
I am kind of cringing at the whole conversation in light of your software choice being Acrobat Pro. Last I checked, Adobe still hadn't updated that app to take advantage of multiple cores. I found this out when I upgraded from a dual core to a quad core back in 2018, only to find that my OCR performance in Acrobat Pro didn't change at all.
I soon after switched to a command-line tool called OCRMyPDF, which does utilize all cores, and my OCR speed went up by a factor of around three. It's not actually as efficient as Adobe with single-core performance, but the fact that it enabled the rest of the cores meant it ultimately went a good deal faster.
I just upgraded myself from the quad-core i5 to a 10-core M1 Pro, but haven't had the chance to do a head-to-head performance test yet. When I get the chance, I will run the same file through the program on my M1 Pro and on my six-core i5 Mac Mini. I expect the M1 to be a bit over twice as fast, in OCRmyPDF, but in Acrobat, I expect the M1 to be about the same or possibly even slower, if it has to run through Rosetta. But I'm curious what results you found.