What do you mean? If they're both available they should be compared. Are we just going to infinitely be waiting to compare chips between Apple and AMD?What is the value of a raw performance comparison between two SoCs with such different consumptions?
Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
[CPU only] Apple M1/2(Max/Ultra) (TSMC 5nm) vs AMD Zen 4 (TSMC 5nm) - Technical Analysis
- Thread starter exoticSpice
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Why not? I want to see AMD's best CPU and that will on the Raphael in the consumer desktop space.Phoenix and Dragon Range will have better performance/consumption than Raphael. Why make a comparison against a worse SoC?
What is the value of a raw performance comparison between two SoCs with such different consumptions?
Well, one of the main criticisms of comparing Apple to x86 was the node advantage. By looking at the performance achievable with Zen4 at 5nm (and the per-core power consumption) we can gain more insight in how the underlying architectures stack agains each other.
Note that I am not suggesting in comparing the system power consumption (desktop Zen will always be at the disadvantage due to the inclusion of relatively power-hungry I/O die). But per-core power and performance can be manipulated, and it's unlikely that mobile Zen4 will behave much differently here.
I thought AMD pushes desktop CPUs past the performance/consumption sweet spot to compete with Intel for the fastest CPU for gaming, so they are less efficient than their mobile CPUs.Well, one of the main criticisms of comparing Apple to x86 was the node advantage. By looking at the performance achievable with Zen4 at 5nm (and the per-core power consumption) we can gain more insight in how the underlying architectures stack agains each other.
Note that I am not suggesting in comparing the system power consumption (desktop Zen will always be at the disadvantage due to the inclusion of relatively power-hungry I/O die). But per-core power and performance can be manipulated, and it's unlikely that mobile Zen4 will behave much differently here.
I thought AMD pushes desktop CPUs past the performance/consumption sweet spot to compete with Intel for the fastest CPU for gaming, so they are less efficient than their mobile CPUs.
Sure, but you can still manipulate the power target of the CPU to make it behave as close as possible to the mobile core. This assuming that the cores themselves are identical between these chips.
The big difference is that mobile CPUs are monolithic SoCs while the desktop ones use multi-chip architecture with the relatively inefficient I/O die. This will make the package power consumption higher on desktop than on the mobile, but should not affect the core power consumption much.
Zen 4 I/O die will move to 6nm TSMC. With Zen 4, AMD's I/O die will shift from 14nm to 6nm, move from GlobalFoundries to TSMC.desktop Zen will always be at the disadvantage due to the inclusion of relatively power-hungry I/O die
So a VERY big improvement for the I/O die

AMD Releases New Details on Zen 4-Powered Ryzen 7000 Family, Upcoming AM5 Chipsets - ExtremeTech
AMD has shared new details on its Zen 4 / Ryzen 7000 platform at Computex 2022. The new CPUs should be available later this year.
 www.extremetech.com
www.extremetech.com
Zen 4 I/O die will move to 6nm TSMC. With Zen 4, AMD's I/O die will shift from 14nm to 6nm, move from GlobalFoundries to TSMC.
So a VERY big improvement for the I/O die
AMD Releases New Details on Zen 4-Powered Ryzen 7000 Family, Upcoming AM5 Chipsets - ExtremeTech
AMD has shared new details on its Zen 4 / Ryzen 7000 platform at Computex 2022. The new CPUs should be available later this year.
Well then! Even more reason to compare everything with everything
")
We forgot that epoch, but across the 80s and the 90s the market of the high end CPU was very rich (Sparc, Alpha, Precision, MIPS, etc etc), with CPUs that where very different; at that time, the benchmark was was very hot. A compiler could spot code coming from benchmark suite and optimize the code accordingly, for example.
From that time, we should all remember one thing: "lies, damns lies and benchmarks".
This not to say benchmarks are useless, but every benchmark should be taken with a grain of salt; syntetic benchmarks are easily faked, and benchmarks based on real applications often show how the real applications is following the technology evolution, more than showing the technology evolution improve performance.
Maurizio
From that time, we should all remember one thing: "lies, damns lies and benchmarks".
This not to say benchmarks are useless, but every benchmark should be taken with a grain of salt; syntetic benchmarks are easily faked, and benchmarks based on real applications often show how the real applications is following the technology evolution, more than showing the technology evolution improve performance.
Maurizio
In retrospect, what may be the greatest contribution of SPEC as a benchmark suite, is the spotlight it put on compilers. Compiler quality, compiler cheating, compiler settings and so on.We forgot that epoch, but across the 80s and the 90s the market of the high end CPU was very rich (Sparc, Alpha, Precision, MIPS, etc etc), with CPUs that where very different; at that time, the benchmark was was very hot. A compiler could spot code coming from benchmark suite and optimize the code accordingly, for example.
From that time, we should all remember one thing: "lies, damns lies and benchmarks".
This not to say benchmarks are useless, but every benchmark should be taken with a grain of salt; syntetic benchmarks are easily faked, and benchmarks based on real applications often show how the real applications is following the technology evolution, more than showing the technology evolution improve performance.
Maurizio
When it comes to hardware vs software, I’d say there is indeed a fair bit of co-evolution going on. That is something of an issue in terms of benchmarking as well as you typically want to be able to compare performance with older systems. ”How much of an improvement would I get if I upgraded to…”. If production software has moved to a new way of doing things, the old benchmark is suddenly a worse predictor. Likewise, increases in cache could mean that benchmarks that once hit main RAM in a realistic fashion now are largely cache resident for the benchmark, but where the current real world jobs have grown in size to still hit main RAM significantly. As with so many things, producing numbers is easy, but understanding what they mean is something else entirely.
For useful comparative purposes you’d like to be able to perform comparisons both across architectures and over time, but both aspects have their own set of pitfalls.
This intrigues me: I wonder where the line is drawn between compiler quality vs. cheating. I mean, fairly obvious 'cheating' is one thing (i.e., the compiler being aware that it's running a particular benchmark, and on-the-fly switching settings to optimize for it), but what about innovations in compiler techniques that other compilers hadn't adopted, yet?In retrospect, what may be the greatest contribution of SPEC as a benchmark suite, is the spotlight it put on compilers. Compiler quality, compiler cheating, compiler settings and so on.
I may be speaking out of turn, but I wonder if certain analysis techniques were seen as cheating when they were first introduced --- I'm thinking things like SSA(I) forms and the analysis/transformations they enable. How far does this line go? Could it be that dynamic settings-adjustment within a compiler isn't cheating per se, but more akin to performance tuning we see with drivers for particular software, with the potential for partial generalization? If the techniques can be broadly applied, then this might be termed a quality metric rather than cheating.
All that said, don't mind me. Just thinking out loud.
This intrigues me: I wonder where the line is drawn between compiler quality vs. cheating. I mean, fairly obvious 'cheating' is one thing (i.e., the compiler being aware that it's running a particular benchmark, and on-the-fly switching settings to optimize for it), but what about innovations in compiler techniques that other compilers hadn't adopted, yet?
I may be speaking out of turn, but I wonder if certain analysis techniques were seen as cheating when they were first introduced --- I'm thinking things like SSA(I) forms and the analysis/transformations they enable. How far does this line go? Could it be that dynamic settings-adjustment within a compiler isn't cheating per se, but more akin to performance tuning we see with drivers for particular software, with the potential for partial generalization? If the techniques can be broadly applied, then this might be termed a quality metric rather than cheating.
All that said, don't mind me. Just thinking out loud.
I don't think that there is an objective way to draw the line. Compilers transform the code, that's the job and there is nothing wrong with that per se. Personally, I think it helps to distinguish between two questions:
1. How fast can I make particular high-level code run using all possible tools and options available to me?
2. How can I compare how different hardware runs particular high-level code?
I think that question 2 (that we are interested in) is more tricky than it might seem. A naive response would be to say, ok, we just need to ensure that the machine code and not the high-level code we end up running is comparable. But the reality is much more difficult. What if the generated machine code is penalised on one type of hardware but runs well on another one and a change to the compiler could make the code to run well on both platforms? (this is something that Intel compiler used to do btw, it generated instructions sequences that were known to be slow on AMD hardware as opposed to be fast on Intel hardware, no idea if they still do it). On the other hand, if one platform supports advanced auto-vectorisation, is it really fair to disable it just because the other platform does not?
Fundamentally all this can be resolved by using a multifactorial approach and evaluate the performance with an array of available compilers, settings as well as tests. But of course, this is tedious and not what users want — they just want to see a single number of "performance", even if that number ends up being fairly arbitrary at the end of the day. Luckily, one can get a fairly reliable estimate by simply using the available state of the art compiler with the default settings for the platform since that's how most software will be compiled.
if one platform supports advanced auto-vectorisation, is it really fair to disable it just because the other platform does not?
It is not about fairness. It is what you want to reason about. If it is strictly the micro architecture you want to compare, then of course vectorization should be disabled if it is not supported by the other toolchain.
If you want to compare platforms, you might as well keep the vectorization enabled.
The same applies to hand optimized assembler code or intrinsics. I typically disable such optimizations, when i want to compare microarchitectures. As example, if you want to compare ARM vs x86 using Blender, make sure that Embree is compiled as pure C-code for both platforms - which you easily can do when compiling Blender and its dependencies from sources.
Last edited:
It is not about fairness. It is what you want to reason about. If it is strictly the micro architecture you want to compare, then of course vectorization should be disabled if it is not supported by the other toolchain.
If you want to compare platforms, you might as well keep the vectorization enabled.
The same applies to hand optimized assembler code or intrinsics. I typically disable such optimizations, when i want to compare microarchitectures. As example, if you want to compare ARM vs x86 using Blender, make sure that Embree is compiled as pure C-code for both platforms - which you easily can do when compiling Blender and its dependencies from sources.
But doesn't this mean adopting the other extreme? Embree is meant to run on SIMD code after all and if you disable the intrinsics you are not getting the representative codegen for the given problem. I do understand the rationale, but this approach subverts expectations and can produce counterintuitive results.
One way to address it is to also take into account software maturity.
From my perspective (do a web search on Radeon quack) benchmarks are only cheating or "unfair" when performance is changed for ONLY the benchmark program. That shows you how well that benchmark could perform, not how well that platform performs overall. This what ATi (now AMD) did with Quake back in the day, and they got caught cheating. What is kind of funny now, is that in the GPU space, most vendors now make application specific tweaks in their drivers, optimizing for new programs as they come out. This begs the question, if the vendor does this for ALL applications, is it still cheating?
But doesn't this mean adopting the other extreme? Embree is meant to run on SIMD code after all and if you disable the intrinsics you are not getting the representative codegen for the given problem. I do understand the rationale, but this approach subverts expectations and can produce counterintuitive results.
One way to address it is to also take into account software maturity.
I do not think it is an extreme position, when giving the architectures to compare equal conditions. I believe thats even the most sensible position.
Angstronomics has more information on Zen 4 just ahead of the presentation.event is on Aug 29


AMD's recent Ryzen 6XXX chips are on 6nm (!) and it's only 10% behind the M2 in single core. On the multi core front, AMD is faster (Geekbench 5).
At 2x-3x expense in power consumption.
Performance per watt is also very close.
Performance per watt is only close if you compare a 4-core Apple chip with an 8-core AMD chip (where AMD is clocked down to bare minimum to reach advantageous position on the efficiency curve), on a benchmark that maximally favors x86 CPUs while penalizing Apple.
AMD will unveil their Ryzen 7XXX chips today and that will get their chips even closer to the M2.
I am sure that 7xxx Ryzen will be faster than M2. The later is a chip designed for passively cooled ultra compact chassis after all. At any rate, I am looking forward to Zen4. Would be nice to finally have comparisons on 5nm.
I have said for a long time that Apple didn't transition the Mac to ARM because it was superior to x86.
ARM is not per se superior (although it is more modern and easier to work with ISA). But Apple transitioned because they have technology that is years ahead of anyone else.
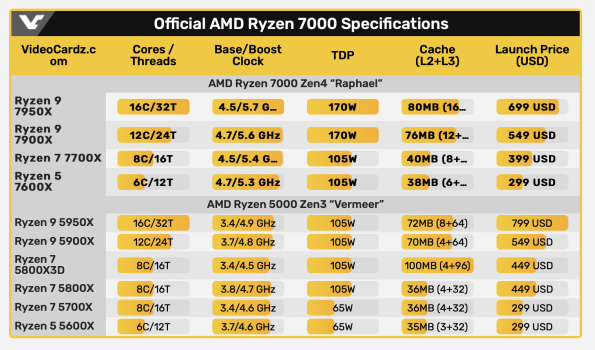
Ok the Ryzen 5 7600X scores 2175 in Geekbench 5. M2 is around 1930 single core.
The base freq of 7600X is 4.7Ghz and M2 is 3.5Ghz. I would say Apple is still in the lead in PPW.
The 7600X is 13% faster in ST(Geekbench only) vs M2.
Last edited:
65% increase on TPD across the board. Looking forward to what it entails to mobile 8xxx series when released.
About 17% single-core advantage to M2 which the P-cores are largely unchanged from the previous A14 core beyond a clock increase, as reported by Anandtech at the time. If we ever have M-chips based on an upcoming A16 cores manufactured on 5nm it will be a interesting comparison.
About 17% single-core advantage to M2 which the P-cores are largely unchanged from the previous A14 core beyond a clock increase, as reported by Anandtech at the time. If we ever have M-chips based on an upcoming A16 cores manufactured on 5nm it will be a interesting comparison.
Attachments
Last edited:
Interesting. AMD earlier said the 7950X was going to have SC performance 15% higher than the 5950X, but this slide says it's 2275/1685 => 35% faster.View attachment 2048719
Ok the Ryzen 5 7600X scores 2175 in Geekbench 5. M2 is around 1930 single core.
The base freq of 7600X is 4.7Ghz and M2 is 3.5Ghz. I would say Apple is still in the lead in PPW.
The 7600X is 13% faster in ST(Geekbench only) vs M2.
Were they knowingly under-promising (either b/c 'under-promise/over-deliver' looks good, or to avoid causing consumers to delay purchasing AMD products until the next gen came out), or were they being conservative because they didn't know just how the final production models would turn out?
They mentioned 13% IPC gains, which is measured at the same clock speed across Zen 3 & 4 genrations.Interesting. AMD earlier said the 7950X was going to have SC performance 15% higher than the 5950X, but this slide says it's 2275/1685 => 35% faster.
Were they knowingly under-promising (either b/c 'under-promise/over-deliver' looks good, or to avoid causing consumers to delay purchasing AMD products until the next gen came out), or were they being conservative because they didn't know just how the final production models would turn out?
For example how much each scores in GB 5 when the clock speed is locked @ 4Ghz.
But the thing is Zen 4 can go up to 5.7Ghz while Zen 3 stuck at 4.7Ghz hence the ~30% SC overall gains in tests.
Register on MacRumors! This sidebar will go away, and you'll see fewer ads.