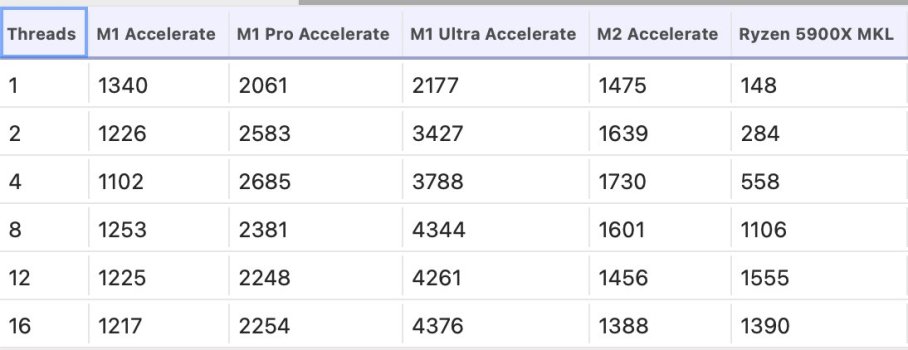
View attachment 2144999
Half the M1 Pro's P-CPU can perform 1600 GFLOPS FP32. That is 500 FLOPs/cycle @ 3.2 GHz. FFMA takes 4 cycles to complete because of physics, so the entire hardware does 2000 FLOP's in 4 cycles. 2000 FLOP's is 1000 FMAs, so you multiplied 32 floats* with 32 floats to get 1024 floats. The entire unit, however, divided that into chunks. Each block contains 1/4 the compute power captured in the image above. Therefore one block cannot multiply all of the 32 floats (or perhaps it does, but takes 16 cycles to do so???).
* When I say floats, I mean 32-bit floats. You could fit 16 of these into a 512-bit register. A double is 64-bit, 8 fit into a 512-bit register. A half is 16-bit, 32 fit into a 512-bit register.
My interpretation, one block multiplies 16 floats or 8 doubles. That is 512 bits or 64 bytes, the same as an AMX register size. Apple can scale the number of AMX blocks to increase each AMX-cluster's compute power. The E-cores have two AMX blocks inside their cluster, and subsequently half the compute power (at equal clocks) as either P-cluster. M2 Pro AMX-clusters have 8 blocks, and subsequently twice the compute power as M1 Pro. Whether the ISA implements that by breaking up larger multiplications into 512-bit by 512-bit chunks, I do not consider.
I remember posting something on MacRumors. I found the theoretical number of transistors necessary to multiply two 16-bit integers. I used it to predict the size of an ANE "core" with striking accuracy. My mental model, AMX blocks and ANE cores are very similar. Each takes a 512-bit chunk of X, 512-bit chunk of Y, and multiplies them in 4 clock cycles. The ANE matrix multiplier variant would multiply 32 halfs x 32 halfs = 1024 half-precision multipliers.
9,000 transistors make up a 16-bit x 16-bit integer multiplier*. That resolves to 9,216,000 transistors per ANE core, or 147,456,000 transistors for the ALUs in the entire M1 neural engine. TSMC N5 has 138.2 million transistors per square millimeter. Therefore our lower bound is 1.067 mm^2.
*I'm treating 16-bit floats (half-precision) just like 16-bit ints. We actually have 11-bit multipliers creating 22-bit products, with extra circuit complexity to process exponents and add stuff. I say a simple 16-bit multiplier is a conservative estimate of transistor count.
Now, take the M1 die shot and look at the 16 things sticking out from the edges of the ANE's center. Narrow down your vision to the silvery part (which is compute), ignoring the brown stuff surrounding that. Those are ANE cores. Visually rearrange them into one contiguous chunk. What you get is smaller than a GPU core (3 mm^2). Perhaps this area is actually 2 mm^2. My conservative estimate (1.067 mm^2) is (a) lower and (b) quite close. That cannot be a coincidence. Let's recap.
----
I don't care how data is dispatched to a unit. Perhaps an AMX block or ANE core takes 1024 bits of data. Splits them into 512-bit chunks, takes 4 cycles to multiply each chunk, 16 cycles overall. Still the same amount of GFLOPS, same amount of transistors.
1) I have direct way to map GFLOPS/(4-)clock to number of transistors, and therefore area on the die. Unlike GPU and CPU, matrix multipliers are the most dense arithmetic circuitry physically possible. You can correlate GFLOPS to die area, perhaps within a factor of 2.
2) Based on performance benchmarks, the AMX does not have any special FP16-multiplying hardware. Please prove me wrong, and provide a test where my M1 Max CPU gets 6.6 TFLOPS FP16. FP32 and FP16 GFLOPS are the same. The assembly ISA might work with FP16 data types, but hardware ultimately decompresses them to FP32. Then it feeds them into 256 single-precision multipliers. They cost (from Wikipedia) ~21,000 transistors. Overall, that's 5,376,000 transistors per AMX block. Less than ANE, but there's a catch. These transistors can be repurposed into 64 double-precision multipliers. That's got to drive up transistor cost, plus the 64-bit mantissa adders and other overheads.
3) Finally, I assume one AMX block consumes more transistors than one ANE core. In theory it's ~5,376,000 vs ~9,000,000 but in reality probably ~20,000,000 vs ~18,000,000. Do the math and overlay the die area onto one of the M1-series die shots.