Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
iMac Pro - First Hands On Thread
- Thread starter bplein
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
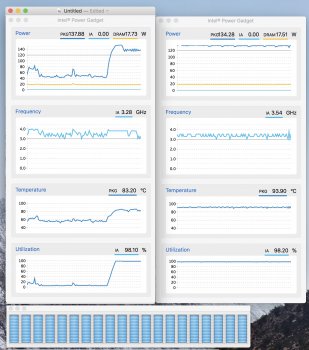
Here you go.
I saved a screenshot of the initial ramp up (the charts on the left) and then let it keep running until everything hit steady state (on the right).
Nick
Thanks Nick. That picture is worth its weight in gold. Basically, we need a much longer benchmark on the CPU to tell the actual performance as that picture shows the 8 core should out perform the 10 core on single thread, & the multi thread performance actually matches geek bench. There appears to be a bit more thermal throttling going on there with the 10 core. I'm definitely happy with my 8 core now. It's not to say that you got ripped off...especially if you're a high cpu user like myself. I just don't do enough work to benefit enough from the extra savings off the 10 core vs what I already get from the 8 core over the i7.
[doublepost=1514502011][/doublepost]
One more thing, could you keep the intel gadget up & also run only geek bench to see what the temps & clock are doing with that please?Here you go.
I saved a screenshot of the initial ramp up (the charts on the left) and then let it keep running until everything hit steady state (on the right).
Nick
Thanks Nick. That picture is worth its weight in gold. Basically, we need a much longer benchmark on the CPU to tell the actual performance as that picture shows the 8 core should out perform the 10 core on single thread, & the multi thread performance actually matches geek bench. There appears to be a bit more thermal throttling going on there with the 10 core. I'm definitely happy with my 8 core now. It's not to say that you got ripped off...especially if you're a high cpu user like myself. I just don't do enough work to benefit enough from the extra savings off the 10 core vs what I already get from the 8 core over the i7.
From what I'm seeing in my app testing, the case for the 10-core is purely about getting the higher clock speed. While anything above 8-10 cores will likely (depending on the specific multi-core optimizations of your software) see rapidly diminishing returns, and in some cases you may actually see slower processing times due to core management algorithms originally written with 4-core processors in mind. Where data is loaded and processed on all cores together at one time (like a horse race), and 90+% of the cores are forced to wait for the outliers to finish before receiving new data. Causing the utilization on 8-10 core Xeons to never go over 50-60% of their theoretical maximum.
Which is why every 4-core computer I have is smoking my new iMP on CPU processing. In the horse-race model, the 4-core chips are less likely to hit those computation outliers in any particular run, and when they do hit them, only 3 cores are forced to wait on the outliers instead of 7 or 9. That, combined with their higher clock speeds, means that they come much closer to hitting their theoretical maximum performance.
So really, 8-cores should be more than enough for 99% of the 1% of users the iMP is aimed at. Ten if you want slightly better single-thread performance. If you go higher than 8-10, you should be intimately familiar with how your apps feed data to their cpu cores, and know beforehand that more cores will help rather than hinder your computation.
Given the problems with core usage in apps not directly optimized by Apple, the real advantage of the extra cores is simply being able to work in 2-3 demanding programs concurrently without any noticeable slowdown. That's a valuable advantage, but one that you could also achieve by buying two lesser computers that are each optimized for their specific tasks.
EDIT: This lack of real-world performance is not a new problem in the realm of high-core count workstations. Here's a link to a posting by a Windows user who's brand new HP workstation (16 cores, 32 threads) was smoked by a MacBook Pro (4 cores, 8 threads) due to poor app optimization.
https://forum.affinity.serif.com/in...xeon-cores-slower-than-8-core-i7-macbook-pro/
Last edited:
From what I'm seeing in my app testing, the case for the 10-core is purely about getting the higher clock speed. While anything above 8-10 cores will likely (depending on the specific multi-core optimizations of your software) see rapidly diminishing returns, and in some cases you may actually see slower processing times due to core management algorithms originally written with 4-core processors in mind. Where data is loaded and processed on all cores together at one time (like a horse race), and 90+% of the cores are forced to wait for the outliers to finish before receiving new data. Causing the utilization on 8-10 core Xeons to never go over 50-60% of their theoretical maximum.
Which is why every 4-core computer I have is smoking my new iMP on CPU processing. In the horse-race model, the 4-core chips are less likely to hit those computation outliers in any particular run, and when they do hit them, only 3 cores are forced to wait on the outliers instead of 7 or 9. That, combined with their higher clock speeds, means that they come much closer to hitting their theoretical maximum performance.
So really, 8-cores should be more than enough for 99% of the 1% of users the iMP is aimed at. Ten if you want slightly better single-thread performance. If you go higher than 8-10, you should be intimately familiar with how your apps feed data to their cpu cores, and know beforehand that more cores will help rather than hinder your computation.
Given the problems with core usage in apps not directly optimized by Apple, the real advantage of the extra cores is simply being able to work in 2-3 demanding programs concurrently without any noticeable slowdown. That's a valuable advantage, but one that you could also achieve by buying two lesser computers that are each optimized for their specific tasks.
EDIT: This lack of real-world performance is not a new problem in the realm of high-core count workstations. Here's a link to a posting by a Windows user who's brand new HP workstation (16 cores, 32 threads) was smoked by a MacBook Pro (4 cores, 8 threads) due to poor app optimization.
https://forum.affinity.serif.com/in...xeon-cores-slower-than-8-core-i7-macbook-pro/
I've been using a few other benchmarks to test out the single threaded performance & have conformed that the longer the 10 core runs, the worse it does against the 8 core...again, single threaded ops only. Think of it as a race, one person starts off sprinting & does great over the first lap, but the second person has a steady pace & eventually overtakes the first...ie, slow & steady wins the race. Your diminishing returns definitely happens at the 8 core point. It may actually occur before that, but we don't have 6 cores as an option to test. With the single threaded ops, the i7 definitely overtakes all the Xeons.
I've been using a few other benchmarks to test out the single threaded performance & have conformed that the longer the 10 core runs, the worse it does against the 8 core...again, single threaded ops only. Think of it as a race, one person starts off sprinting & does great over the first lap, but the second person has a steady pace & eventually overtakes the first...ie, slow & steady wins the race. Your diminishing returns definitely happens at the 8 core point. It may actually occur before that, but we don't have 6 cores as an option to test. With the single threaded ops, the i7 definitely overtakes all the Xeons.
Maybe you missed my point, but my i7's (2015 iMac, home-built PC) are significantly smoking the iMP in some MULTI-CORE tests, not just in single-threaded apps. The issue is that the apps (or their libraries) are optimized for 4-core processors, and don't scale well at all beyond that.
Take Agisoft Photoscan, for instance. When building a point cloud, or later a mesh from that cloud, all of the processor cores are given data at the same time. But ALL OF THEM have to complete the run before any new data is loaded. So when the run first starts, the processor is running at ~75% utilization. But on every 3rd or 4th run, it dips down to ~5-10% for 2-3 seconds because 18-19 of my core threads have completed, but one or two outliers are still processing the run. It's analogous to a horse race where everyone is standing around waiting on one injured horse to walk over the finish line before the next race can start.
But if you're running 8 threads at a time instead of 20, you're much less likely to have a "walking horse" on any given individual run. So they hit fewer stalls, and the effect of each stall is much less damaging to overall performance because fewer cores are kept waiting for new data.
I mean, here's my mesh generation figures from my CPU tests:
#1 – Home built 4-core i7 PC @ 1588 seconds
#2 – Late 2015 27" iMac @ 2460 seconds
#3 – iMac Pro 10-Core @ 3116 seconds (51% of PC speed)
If the program was able to use one of the 10 cores to feed new horses (data) as needed, instead of all at once, none of the cores would be sitting around waiting, and performance would drastically improve. But setting aside one core for data management like that would be worse for a 4-core processor than the one-race-at-a-time approach.
Even when the scores are better for the iMP, they're often not drastically better:
Dense Point Cloud Generation...
#1 iMac Pro 10-Core @ 1133 seconds (only 37% faster than 4-core PC)
#2 Home built 4-core i7 PC @ 1554 seconds
#3 Late 2015 27" iMac @ 1671 seconds
This is different from something like RAW processing in Photoshop. Where the 10 cores make a huge difference to loading times, and how fast updates to multiple images are shown. But then you save out the files and it's no faster than before because that function is single-threaded.
Last edited:
Is it logical to expect that, over time, and hopefully in the near term, developers will only increase optimization and utilization of 6/8/10 or more cores? Does an app need to be developed specifically for a certain amount of cores, or can they be made to scale to what's available on a given machine?
Maybe you missed my point, but my i7's (2015 iMac, home-built PC) are significantly smoking the iMP in some MULTI-CORE tests, not just in single-threaded apps. The issue is that the apps (or their libraries) are optimized for 4-core processors, and don't scale well at all beyond that.
Take Agisoft Photoscan, for instance. When building a point cloud, or later a mesh from that cloud, all of the processor cores are given data at the same time. But ALL OF THEM have to complete the run before any new data is loaded. So when the run first starts, the processor is running at ~75% utilization. But on every 3rd or 4th run, it dips down to ~5-10% for 2-3 seconds because 18-19 of my core threads have completed, but one or two outliers are still processing the run. It's analogous to a horse race where everyone is standing around waiting on one injured horse to walk over the finish line before the next race can start.
But if you're running 8 threads at a time instead of 20, you're much less likely to have a "walking horse" on any given individual run. So they hit fewer stalls, and the effect of each stall is much less damaging to overall performance because fewer cores are kept waiting for new data.
I mean, here's my mesh generation figures from my CPU tests:
#1 – Home built 4-core i7 PC @ 1588 seconds
#2 – Late 2015 27" iMac @ 2460 seconds
#3 – iMac Pro 10-Core @ 3116 seconds (51% of PC speed)
If the program was able to use one of the 10 cores to feed new horses (data) as needed, instead of all at once, none of the cores would be sitting around waiting, and performance would drastically improve. But setting aside one core for data management like that would be worse for a 4-core processor than the one-race-at-a-time approach.
Even when the scores are better for the iMP, they're often not drastically better:
Dense Point Cloud Generation...
#1 iMac Pro 10-Core @ 1133 seconds (only 37% faster than 4-core PC)
#2 Home built 4-core i7 PC @ 1554 seconds
#3 Late 2015 27" iMac @ 1671 seconds
This is different from something like RAW processing in Photoshop. Where the 10 cores make a huge difference to loading times, and how fast updates to multiple images are shown. But then you save out the files and it's no faster than before because that function is single-threaded.
Run your tests again with the software using only 4 cores on each machine. For the machines with more than 4 cores simply turn off the extra cores to make the software run on 4 cores.
sudo nvram boot-args="cpus=4" & Restart
Last edited:
Is it logical to expect that, over time, and hopefully in the near term, developers will only increase optimization and utilization of 6/8/10 or more cores? Does an app need to be developed specifically for a certain amount of cores, or can they be made to scale to what's available on a given machine?
Whether or not developers will optimize for more than 4 cores (or whatever consumer chips have in the future) will depend on their market. The extremely expensive niche products like Maya will optimize for workstation-class machines first (if they haven't already), because that's what a large proportion of their users (especially the big film/game studios) are running on. The more mass-market apps like PhotoScan or Photoshop may see little upside to optimizing for more than 4 cores unless they can charge enough for a "pro" version to make a business case for the extra development time. Or unless they can just buy a code library that does all the hard work for them.
As far as the optimizations themselves, I'm not an expert on this subject. But I do think the run-the-horses-together algorithm probably works better on ~4 cores. After that you'll have some number of cores that really need to be set aside to feed the others for higher throughput. But that's going to depend on a lot of factors. It may even be that the all-horses-at-once algorithm is still preferable because of how the CPU caches are addressed by the cores. Which you could only get around by adding more CPUs with fewer cores each. Whatever the case, it's a complex problem with no easy answers.
[doublepost=1514585861][/doublepost]
Run your tests again with the software using only 4 cores on each machine. For the machines with more than 4 cores simply turn off the extra cores to make the software run on 4 cores.
sudo nvram boot-args="cpus=4" & Restart
I was just looking for how to do that. Thanks!
Last edited:
I was just looking for how to do that. Thanks!
Somewhat simpler is to launch Instruments.app (if you have Xcode installed), go to its Preferences menu, choose CPUs and pick however many you want, +/- hyperthreading. Changed on the fly, no reboot required.
Somewhat simpler is to launch Instruments.app (if you have Xcode installed), go to its Preferences menu, choose CPUs and pick however many you want, +/- hyperthreading. Changed on the fly, no reboot required.
Even better!
Maybe you missed my point, but my i7's (2015 iMac, home-built PC) are significantly smoking the iMP in some MULTI-CORE tests, not just in single-threaded apps. The issue is that the apps (or their libraries) are optimized for 4-core processors, and don't scale well at all beyond that.
Take Agisoft Photoscan, for instance. When building a point cloud, or later a mesh from that cloud, all of the processor cores are given data at the same time. But ALL OF THEM have to complete the run before any new data is loaded. So when the run first starts, the processor is running at ~75% utilization. But on every 3rd or 4th run, it dips down to ~5-10% for 2-3 seconds because 18-19 of my core threads have completed, but one or two outliers are still processing the run. It's analogous to a horse race where everyone is standing around waiting on one injured horse to walk over the finish line before the next race can start.
But if you're running 8 threads at a time instead of 20, you're much less likely to have a "walking horse" on any given individual run. So they hit fewer stalls, and the effect of each stall is much less damaging to overall performance because fewer cores are kept waiting for new data.
I mean, here's my mesh generation figures from my CPU tests:
#1 – Home built 4-core i7 PC @ 1588 seconds
#2 – Late 2015 27" iMac @ 2460 seconds
#3 – iMac Pro 10-Core @ 3116 seconds (51% of PC speed)
If the program was able to use one of the 10 cores to feed new horses (data) as needed, instead of all at once, none of the cores would be sitting around waiting, and performance would drastically improve. But setting aside one core for data management like that would be worse for a 4-core processor than the one-race-at-a-time approach.
Even when the scores are better for the iMP, they're often not drastically better:
Dense Point Cloud Generation...
#1 iMac Pro 10-Core @ 1133 seconds (only 37% faster than 4-core PC)
#2 Home built 4-core i7 PC @ 1554 seconds
#3 Late 2015 27" iMac @ 1671 seconds
This is different from something like RAW processing in Photoshop. Where the 10 cores make a huge difference to loading times, and how fast updates to multiple images are shown. But then you save out the files and it's no faster than before because that function is single-threaded.
You bring up an important and excellent point I have not really discussed because I made my decision based on multi-cores.
Every user needing CPU power needs to know if they need the single core or multi core performance. This involves knowing how your software performs. Handbrake uses all of every core well, where your examples are in between multi thread and single thread ops that clearly benefit from fewer and faster cores. Others can only use one thread whereas some people just don't need the CPU power at all.
You are such a class act RuffDraft! I really enjoy the story of how you arrived at where you're at today. Fun to read, fun to imagine the possibilities that lie ahead, and fun to discuss. I have a feeling your business will continue to grow and you'll do really well...all while having fun too. (That is what its all about, right?)
Of course we'll continue to stay in touch here and especially as we learn more about the iMac Pro, but if our paths ever cross in real life, the beverages of choice will be on me.
Cheers,
Bryan
I'm not so sure that I deserve those accolades, but thank you very much.
It's definitely about having fun, and I hope you have as many fun trips on the road next year as you have this year!
All the best for the new year!!
Whether or not developers will optimize for more than 4 cores (or whatever consumer chips run in the future) will depend on their market. The extremely expensive niche products like Maya will optimize for workstation-class machines first (if they haven't already), because that's what a large proportion of their users (especially the big film/game studios) are running on. The more mass-market apps like PhotoScan or Photoshop may see little upside to optimizing for more than 4 cores unless they can charge enough for a "pro" version to make a business case for the extra development time. Or unless they can just buy a code library that does all the hard work for them.
As far as the optimizations themselves, I'm not an expert on this subject. But I do think the run-the-horses-together algorithm probably works better on ~4 cores. After that you'll have some number of cores that really need to be set aside to feed the others for higher throughput. But that's going to depend on a lot of factors. It may even be that the all-horses-at-once algorithm is still preferable because of how the CPU caches are addressed by the cores. Which you could only get around by adding more CPUs with fewer cores each. Whatever the case, it's a complex problem with no easy answers.
[doublepost=1514585861][/doublepost]
I was just looking for how to do that. Thanks!
Somewhat simpler is to launch Instruments.app (if you have Xcode installed), go to its Preferences menu, choose CPUs and pick however many you want, +/- hyperthreading. Changed on the fly, no reboot required.
Nice addition given by redshift27 above.
")
You can easily check you've set the core count correctly by selecting the Activity Monitor's Windows->CPU Usage. If you've set it to 4 then only 4 of the histograms will be active. Be sure to reset things when you're done testing.
I've been using a few other benchmarks to test out the single threaded performance & have conformed that the longer the 10 core runs, the worse it does against the 8 core...again, single threaded ops only. Think of it as a race, one person starts off sprinting & does great over the first lap, but the second person has a steady pace & eventually overtakes the first...ie, slow & steady wins the race. Your diminishing returns definitely happens at the 8 core point. It may actually occur before that, but we don't have 6 cores as an option to test. With the single threaded ops, the i7 definitely overtakes all the Xeons.
So are you or others seeing in these benchmarks that the 10 core’s higher turbo boost eventually does not make up for the lower base clock when it comes to single thread? Which benchmarks and how long are we talking about before the 8 core outperforms the 10 core? I’m about to place my order
Agisoft Photoscan ... mesh generation figures from my CPU tests:
#1 – Home built 4-core i7 PC @ 1588 seconds
#2 – Late 2015 27" iMac @ 2460 seconds
#3 – iMac Pro 10-Core @ 3116 seconds (51% of PC speed)
Looking forward to seeing the effects of shutting off 6 cores for this software. Quite eye opening.
Maybe it really doesn't like Xeons. Could it be using something in the i7 that a Xeon doesn't have?
So are you or others seeing in these benchmarks that the 10 core’s higher turbo boost eventually does not make up for the lower base clock when it comes to single thread? Which benchmarks and how long are we talking about before the 8 core outperforms the 10 core? I’m about to place my order
As an owner of the 10-Core, I would advise buying the higher base-clocked 8-core instead. If the iMac had a decent GPU, I'd seriously consider returning the iMP for a regular iMac with an 4+Ghz i7 chip. But not when the best GPU they're offering is an RX580.
[doublepost=1514607122][/doublepost]
Looking forward to seeing the effects of shutting off 6 cores for this software. Quite eye opening.
Maybe it really doesn't like Xeons. Could it be using something in the i7 that a Xeon doesn't have?
Working on the new benchmarks. They take time.
The i7 has a much higher native clock speed. That's the killer. Their own docs recommend 4-core i7's over CPUs with more cores. Maybe it will change if they utilize the new vector instructions in the new Xeon chips we have, or aggressively re-factor their code for high number of CPUs.
Considering the nVidia advantage in raw GPU processing (fewer cores clocked higher) over AMD GPUs (more cores clocked lower) we may be looking at a fundamental computational wall that Intel has no idea how to climb. They can't meaningfully raise clock speeds beyond 4Ghz, and substituting large numbers of slower cores seems to encounter diminishing returns very quickly. Plus GPUs scale much better than CPUs. So essentially CPUs have just become feeder mechanisms for GPUs, rather than a computational end in themselves.
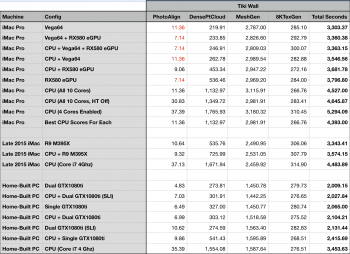
[doublepost=1514608573][/doublepost]New Benchmarks (see screenshot).
Red numbers for the Vega tests indicate CPU calculations being substiituted for Vega tests that would have crashed when run due to a bug of some kind.
4 cores wasn't any faster than 10 (although the actual difference was slight for the mesh generation). What did boost the mesh generation time past the 10-core baseline was turning off hyper threading for the 10 core run. But this made the other calculation steps run slower, resulting in a net loss. If you're willing to switch hyper threading on and off per-step, then you can gain 5% in overall processing. Woohoo! (not). Even the best combination of settings is still 27% slower than a 4Ghz i7 running in Windows.
Time to move on to other software tests...
Attachments
Last edited:
Adding an interesting data point for discussion purposes.
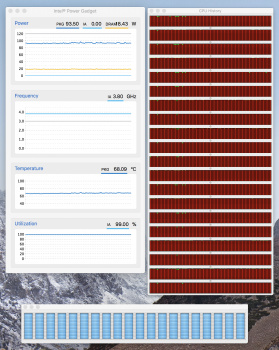
I launched photos earlier today and apparently it's been busy downloading a bunch of photos from iCloud and is now running some ML algorithms. There was a thread called photoanalysisd taking a bunch of cycles when I first unlocked, but now we're back to Photos itself churning resources. When I look through the app I see it's about 1000 of 6500 photos through the facial recognition scan, so I'm guessing that's what's eating up CPU time.
What is surprising is that we're landing at some new numbers [again for 10-core].
Still 99% utilization.
This time settling at 3.8Ghz [vs 3.5 I saw with the yes test] and temps are ~70C [vs 90+ with yes]
Nick
I launched photos earlier today and apparently it's been busy downloading a bunch of photos from iCloud and is now running some ML algorithms. There was a thread called photoanalysisd taking a bunch of cycles when I first unlocked, but now we're back to Photos itself churning resources. When I look through the app I see it's about 1000 of 6500 photos through the facial recognition scan, so I'm guessing that's what's eating up CPU time.
What is surprising is that we're landing at some new numbers [again for 10-core].
Still 99% utilization.
This time settling at 3.8Ghz [vs 3.5 I saw with the yes test] and temps are ~70C [vs 90+ with yes]
Nick
Attachments
Potential buyer later on this coming year. I use Final Cut a lot, primarily for h.264 edits with some color correction (generally no stabalization needed). My question is, does iMac Pro have QuickSync? I was watching a video from DetroitBorg where he said it didn’t have QuickSync and thus H.264 endcoding was faster on the regular iMac 5k. I thought the newer Xeons had a built in GPU just for QuickSync? Or is that limited to the mobile Xeons? TIA!
Running raw calculations, prime95, & a few others. Basically, the 8 core doesn’t not get hot enough to drop below 3.9GHz, but the 10 core does & drops to about 3.5. Not a big difference. I’m very happy with the 8 core. Another poster brought up some software that waits for operations to complete before next assignment. This means fewer cores helps. It really all depends on what software you intend to use. For me, handbrake, which loves cores. The difference between the 8 & 10 multi thread is 10 mins over an hour. I decided that wasn’t worth $800. I also wanted a faster single core, which had me concerned until I found that the 8c drops to 3.9 instead of 3.2. It’s not i7 speeds there, but it does the job & grinds handbrake & three operating systems at the same time very well.So are you or others seeing in these benchmarks that the 10 core’s higher turbo boost eventually does not make up for the lower base clock when it comes to single thread? Which benchmarks and how long are we talking about before the 8 core outperforms the 10 core? I’m about to place my order
Get the memory you think you’ll need now unless it’s 128c then you’re crazy or wealthy. Vega 64 is probably worth it.
[doublepost=1514621198][/doublepost]
Potential buyer later on this coming year. I use Final Cut a lot, primarily for h.264 edits with some color correction (generally no stabalization needed). My question is, does iMac Pro have QuickSync? I was watching a video from DetroitBorg where he said it didn’t have QuickSync and thus H.264 endcoding was faster on the regular iMac 5k. I thought the newer Xeons had a built in GPU just for QuickSync? Or is that limited to the mobile Xeons? TIA!
I’m out right now for a few days, but I’ll double check. Keep in mind that QS quality is not up to Software quality.
[doublepost=1514621386][/doublepost]
As an owner of the 10-Core, I would advise buying the higher base-clocked 8-core instead. If the iMac had a decent GPU, I'd seriously consider returning the iMP for a regular iMac with an 4+Ghz i7 chip. But not when the best GPU they're offering is an RX580.
[doublepost=1514607122][/doublepost]
Working on the new benchmarks. They take time.
The i7 has a much higher native clock speed. That's the killer. Their own docs recommend 4-core i7's over CPUs with more cores. Maybe it will change if they utilize the new vector instructions in the new Xeon chips we have, or aggressively re-factor their code for high number of CPUs.
Considering the nVidia advantage in raw GPU processing (fewer cores clocked higher) over AMD GPUs (more cores clocked lower) we may be looking at a fundamental computational wall that Intel has no idea how to climb. They can't meaningfully raise clock speeds beyond 4Ghz, and substituting large numbers of slower cores seems to encounter diminishing returns very quickly. Plus GPUs scale much better than CPUs. So essentially CPUs have just become feeder mechanisms for GPUs, rather than a computational end in themselves.
[doublepost=1514608573][/doublepost]New Benchmarks (see screenshot).
Red numbers for the Vega tests indicate CPU calculations being substiituted for Vega tests that would have crashed when run due to a bug of some kind.
4 cores wasn't any faster than 10 (although the actual difference was slight for the mesh generation). What did boost the mesh generation time past the 10-core baseline was turning off hyper threading for the 10 core run. But this made the other calculation steps run slower, resulting in a net loss. If you're willing to switch hyper threading on and off per-step, then you can gain 5% in overall processing. Woohoo! (not). Even the best combination of settings is still 27% slower than a 4Ghz i7 running in Windows.
Time to move on to other software tests...
Thinking about your test, if your software depends on all threads being completed before the next assignements, then hyperthreading would absolutely be horrible for it, especially if the cpu use is good. You can see that on the cpu test of cinebench, the hyperthreading jobs are really slow because the cores have few tansistors left to allocate. Thanks again for posting this info.
[doublepost=1514622273][/doublepost]
Potential buyer later on this coming year. I use Final Cut a lot, primarily for h.264 edits with some color correction (generally no stabalization needed). My question is, does iMac Pro have QuickSync? I was watching a video from DetroitBorg where he said it didn’t have QuickSync and thus H.264 endcoding was faster on the regular iMac 5k. I thought the newer Xeons had a built in GPU just for QuickSync? Or is that limited to the mobile Xeons? TIA!
I just confirmed by remoting in, no quicksync. Thats usually built in on the intel video die.
Where are the new iMac Pro's assembled? curious to know if US made like some of the prior models.
thanks!
thanks!
Potential buyer later on this coming year. I use Final Cut a lot, primarily for h.264 edits with some color correction (generally no stabalization needed). My question is, does iMac Pro have QuickSync? I was watching a video from DetroitBorg where he said it didn’t have QuickSync and thus H.264 endcoding was faster on the regular iMac 5k. I thought the newer Xeons had a built in GPU just for QuickSync? Or is that limited to the mobile Xeons? TIA!
AFAIK, this has not been confirmed yet. but I think that the latest version of Final Cut uses the video encoder hardware built-in to the AMD Radeon Pro Vega.
[doublepost=1514624032][/doublepost]
Where are the new iMac Pro's assembled? curious to know if US made like some of the prior models.
thanks!
china
...I use Final Cut a lot, primarily for h.264 edits with some color correction (generally no stabalization needed). My question is, does iMac Pro have QuickSync? I was watching a video from DetroitBorg where he said it didn’t have QuickSync and thus H.264 endcoding was faster on the regular iMac 5k. I thought the newer Xeons had a built in GPU just for QuickSync? Or is that limited to the mobile Xeons? TIA!
That that is the million-dollar question. No Xeon has ever had Quick Sync except some low-end four-core versions. Some early rumors indicated the iMac Pro used a customized Xeon with Quick Sync. The earliest sketchy FCPX benchmarks indicated the iMP was either using that or maybe the similar UVD/VCE transcoding hardware bundled on AMD GPUs.
However more recent benchmarks are starting to look like the iMP Xeon doesn't have Quick Sync and maybe FCPX isn't using AMD's fixed-function transcoding logic -- at least for H264.
It is a complex and fragmented picture because FCPX on the iMP seems very fast at encoding H265/HEVC which definitely requires some kind of hardware acceleration -- it is about 10x as compute-intensive as H264.
However in the real world, H264 and variants like Sony's XAVC-S and Google's VP9 and AV1 are the dominate codecs today. It is increasingly vital that any computer targeted at video editing must have hardware acceleration for H264 and similar codecs, not just H265/HEVC.
Maybe further benchmarks will illuminate this area but it's a bit disturbing that Max Yuryev's tests showed the 8-core Vega56 iMP was slower on several FCPX H264 benchmarks than a 2017 iMac 27.
Lots of people use other video editing software but FCPX is a good indicator of what's possible since Apple optimizes it for their own hardware. If FCPX isn't using hardware acceleration for H264 on the iMP, that's not a good sign.
Potential buyer later on this coming year. I use Final Cut a lot, primarily for h.264 edits with some color correction (generally no stabalization needed). My question is, does iMac Pro have QuickSync? I was watching a video from DetroitBorg where he said it didn’t have QuickSync and thus H.264 endcoding was faster on the regular iMac 5k. I thought the newer Xeons had a built in GPU just for QuickSync? Or is that limited to the mobile Xeons? TIA!
Max Yuryev over on YouTube has a nice video about Final Cut Pro and the new iMac Pro. Xeons don’t have Quicksync and it seeems in a lot of cases the regular iMac is faster than the iMac Pro. Where the iMac Pro shines is in the 6 and 8k raw videos and encoding in H265 where Quicksync is not optimized.
Also the fact that it does all these things silently as opposed to hearing a vacuum cleaner like the regular iMac
Here’s the link
Played with the 8 core version today.
Final Cut timeline playback of 8K ProRes422 was very good.
Quicktime playback of the same video was so-so. It's still early days for that level of content and generally Mac GPU drivers aren't optimized enough. I'd like to see AMD release the same optimizations for Mac and PC simultaneously with EXACTLY the same hardware feature support.
Final Cut timeline playback of 8K ProRes422 was very good.
Quicktime playback of the same video was so-so. It's still early days for that level of content and generally Mac GPU drivers aren't optimized enough. I'd like to see AMD release the same optimizations for Mac and PC simultaneously with EXACTLY the same hardware feature support.
Last edited by a moderator:
Register on MacRumors! This sidebar will go away, and you'll see fewer ads.