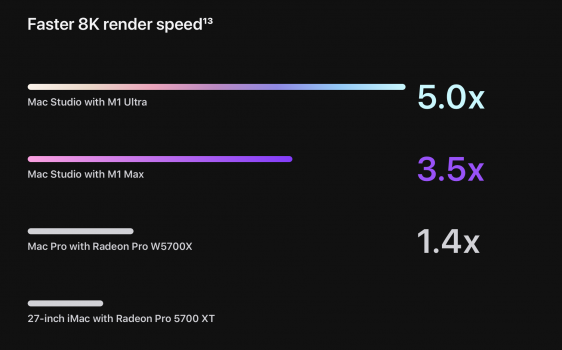
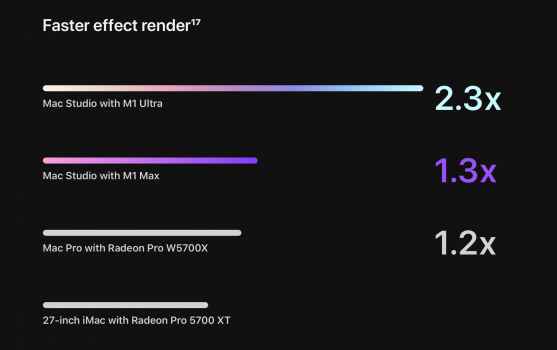
Binning is usually done by deliberately crippling perfectly functional chips. You can't produce lower-end chips in sufficient quantities if you only wait for dies that have flaws in the right parts. Especially not with chips such as the M1 Max, where GPU cores only take a small fraction of total die area.
GPU cores take up a massive proportion of the die area on the M1 Max, like 40%, and there can be multiple technical reasons for binning, it's not always that the core has to be totally non-functional. However, yes, functional chips are sometimes binned down - usually depends on process.
Last edited: