Do you have specific thoughts that you would like to express?AnandTech Forums: Technology, Hardware, Software, and Deals
Seeking answers? Join the AnandTech community: where nearly half-a-million members share solutions and discuss the latest tech.www.anandtech.com
Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
Intel Alder Lake vs. Apple M1
- Thread starter leman
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
My knowledge of SIMD instructions is sketchy at best, so I‘ll use “standard“ instructions for comparison instead. To have a similar complexity, I‘ll use Alpha and ARM64, both 64 bit RISC architectures. We‘ll assume that there is a 1-to-1 translation layer from Alpha to ARM64.SSE2Neon is not emulation, but translation. And we can't judge the performance impact on a specific application without specifiying the instruction mix that it uses. Also, not all intrinsics are equally performance critical. The ones used in the inner loops matter most.
Alpha‘s data processing instructions can only use 8-bit literals. For constants bigger than 255 you‘ll have to use a load instruction or other means to get the value into a register.
ARM64 has a more convoluted literal encoding. If you use a direct translation from Alpha to ARM64, you‘ll have more than one instruction for literals larger than 255, where one instruction might be sufficient for ARM64.
Alpha has a scaled addition instruction, where one operand register is multiplied by 4 or 8 before the addition.
ARM64 can replicate this, because the second operand can be shifted in the same instruction. But while ARM64 can perform this shift over the whole 64 bit of a register, Alpha will need separate shift instruction if the shift is not by 2 or 3 positions. Thus, another wasted instruction when translating from Alpha to ARM64, unless the shift is 2 or 3.
Early RISC architectures had different ways to deal with the latency of a division. Some preformed it in a separate execution unit (MIPS), others in bit-wise division steps (PA-RISC), but Alpha has no division instruction at all.
You can replicate the division calculation by other means, but since ARM64 does have a division instruction, a 1-to-1 translation will definitely lead to inefficient code.
These are just a few examples from somewhat simple SISD instructions. I guess for SIMD instructions the differences could be much bigger.
Thus, your claim that most SSE intrinsics map to one NEON intrinsic doesn‘t mean that the NEON code is good or even optimized, because some calculations could be solved with a different approach and fewer instructions.

An Apple GPU core contains 4x 32-wide ALUs, for 128 ALUs or “shader cores/units” in total. How exactly these work and whether each ALU can execute different instruction stream is not clear as far as I know. The Ultra will therefore contain 8192 “shader cores/units” and should support close to 200000 threads in flight.
I can definitely imagine performance tanking if not enough threads are supplied. GPUs need to hide latency after all.
Okay, I had to test this. I ran a ALU-heavy kernel (with low register pressure) on my M1 Pro on increasingly large arrays to see where the execution time 'jumped', to try to infer how many threads are running at once on M1 GPUs.
This is what I got:
There's one thread for each array element the GPU kernel is run on. Threadgroup size is set to maximum (1,024 threads per threadgroup on M1 Pro). The execution time jumps every 16,384 array elements / threads. If we focus on the first part of the graph, there's a slope between 0 to 1,024 threads:
What is happening here is: since threadgroups are 1,024 threads, if I dispatch any number from 0 to 1,024 threads, they'll all be in a single threadgroup (and executed in the same GPU core). The execution time in this region makes a small jump every 32 threads, and remains flat otherwise. That must be because the GPU core splits the threadgroup in batches of 32 threads (a single SIMD group) and executes those batches one after the other. For a 16-core GPU, only 32*16 = 512 are executing 'at once'.
Once the thread number goes over 1,024, another threadgroup is created, which runs in a different GPU core, in parallel with the first threadgroup, so no extra time is needed as long as there's more GPU cores available.
This goes up to 1,024 (threadgroup) * 16 (cores) = 16,384. If there are more threads, they get bundled in a 17th threadgroup, but since there's only 16 cores in my M1 Pro, that extra threadgroup can't be executed until one of the 16 cores has finished the whole 1,024 thread threadgroup, essentially doubling the time it takes for the whole kernel to run. Another jump happens after 32,768 threads for the same reason (there are 33 full threadgroups for 16 cores, so the 33rd has to run after two full threadgroups have finished execution).
On the M1 Ultra, that'd mean that only 32 (threads per SIMD gorup) * 64 (cores) = 2,048 threads are truly executing 'at once'. However, the time it takes for an extra SIMD group to execute is relatively small (~9 μs in this kernel, the height of the jump between 512 and 512+32 threads) compared to the time it takes to set up a threadgroup (~630 μs for this kernel, the time it takes for just 32 dispatched threads, minus the 9μs of the SIMD group execution time). Therefore it pays off to have the threadgroups as full as possible. So ideally you'd try to have multiples of 1,024 (max threadgroup size) * 64 (cores) = 65,536 threads 'in-flight'.
I think the quoted number of 196,608 threads is 3 times 65,536 because the GPU has a compute, shader and vertex channels, and (probably) those can run concurrently for a total ot 65,536 * 3 = 196,608 threads in-flight. But for a single kernel you'd only need to fill 65,536 at most. Whether that number is high enough to make the M1 Ultra scale poorly, I don't know. But I don't think it's that high.
On the M1 Ultra, that'd mean that only 32 (threads per SIMD gorup) * 64 (cores) = 2,048 threads are truly executing 'at once'. However, the time it takes for an extra SIMD group to execute is relatively small (~9 μs in this kernel, the height of the jump between 512 and 512+32 threads) compared to the time it takes to set up a threadgroup (~630 μs for this kernel, the time it takes for just 32 dispatched threads, minus the 9μs of the SIMD group execution time). Therefore it pays off to have the threadgroups as full as possible. So ideally you'd try to have multiples of 1,024 (max threadgroup size) * 64 (cores) = 65,536 threads 'in-flight'.
I think the quoted number of 196,608 threads is 3 times 65,536 because the GPU has a compute, shader and vertex channels, and (probably) those can run concurrently for a total ot 65,536 * 3 = 196,608 threads in-flight. But for a single kernel you'd only need to fill 65,536 at most. Whether that number is high enough to make the M1 Ultra scale poorly, I don't know. But I don't think it's that high.
Your experiment is a very nice illustration how many threads a GPU can execute simultaneously, but this is not the same as "threads in-flight". I assume that your shader code is fairly simple, right, probably just a sequence of arithmetic operations? Real-world shader code however is full of data stalls: waiting for data, synchronisation barriers etc. When a GPU kernel encounters such a stall, it will attempt to start executing a different kernel instead, so that the hardware has something to do while the memory controller etc. is fetching the data needed. Threads in flight are simply threads that can be paused/resumed at a moment's notice. I am not sure about the actual details on how it's done, but if I understand it correctly, the GPU register file is split between different kernels/threadgroups so that switching between those kernels is instantaneous. The fewer local variables your kernels needs, the more kernels can be kept "on standby" in the register file, the more opportunity does the GPU has for filling the gaps between the stalls. For details, refer to https://dougallj.github.io/applegpu/docs.html
If your kernels would contain non-trivial data dependencies (e.g. they would process some sort of unpredictable data that is used to fetch other data), you would see much lower performance due to stalls. But as you increase the number of scheduled kernels, the performance would improve due to better ALU occupancy. Basically, what all of this means is that you want to submit as many kernels (compute, vertex, fragment, doesn't matter, it's the same stuff anyway) as you can, and make them as independent from each other as you can, to get the best possible performance. It is entirely possible that you app simply does not have enough work to occupy a beefy GPU.
All of this is just background information though and does not explain the lack of scaling with Redshift.
P.S. Apple G13 is still relatively simple and “only” offers 127 FP32 registers per hardware ALU lane. Nvidia and AMD hardware have larger register files and therefore can support more threads in flight. Or more complex shaders without register spilling.
I wasn't even entirely sure as to what they meant with 'in-flight' threads. My main goal was to find out how the GPU worked when dispatching threads of a single task/kernel, to see if scaling could be affected by being less work to do than the number of available execution units.Your experiment is a very nice illustration how many threads a GPU can execute simultaneously, but this is not the same as "threads in-flight".
Yes. It's a loop that generates and sums a lot random numbers onto a single variable, using a LCG PRNG. No memory fetches, other than reading from the input buffer at the start and writing to it at the end.I assume that your shader code is fairly simple, right, probably just a sequence of arithmetic operations?
I think that Apple's GPU cores can only have three different GPU programs 'waiting'/concurrently executing on a single core: one fragment shader, one vertex function, and one compute kernel. Hence the 65,536 * 3 = 196,608 threads in-flight figure Apple quotes (probably due to each type of function having its own caches). I don't think you can have, for example, two compute kernels in a single GPU core. Latency is hidden in those instances just by 'sharing' the latency costs among all executed threads in the SIMD group.Real-world shader code however is full of data stalls: waiting for data, synchronisation barriers etc. When a GPU kernel encounters such a stall, it will attempt to start executing a different kernel instead, so that the hardware has something to do while the memory controller etc. is fetching the data needed. Threads in flight are simply threads that can be paused/resumed at a moment's notice. I am not sure about the actual details on how it's done, but if I understand it correctly, the GPU register file is split between different kernels/threadgroups so that switching between those kernels is instantaneous. The fewer local variables your kernels needs, the more kernels can be kept "on standby" in the register file, the more opportunity does the GPU has for filling the gaps between the stalls. For details, refer to https://dougallj.github.io/applegpu/docs.html
But this kind of problems are, essentially, scheduling/execution-bubble related, they shouldn't affect scaling. You can be underutilizing a GPU by having huge execution bubbles in the pipeline regardless of how beefy the GPU is. But adding more cores should still scale well, as long as the data to process (vertices, pixels, array elements, texture data...) is big enough to feed those programs (hence why I tried to find out how many array elements could be processed at once).If your kernels would contain non-trivial data dependencies (e.g. they would process some sort of unpredictable data that is used to fetch other data), you would see much lower performance due to stalls. But as you increase the number of scheduled kernels, the performance would improve due to better ALU occupancy. Basically, what all of this means is that you want to submit as many kernels (compute, vertex, fragment, doesn't matter, it's the same stuff anyway) as you can, and make them as independent from each other as you can, to get the best possible performance. It is entirely possible that you app simply does not have enough work to occupy a beefy GPU.
The prices for GPU upgrades are interesting, because you pay them only to prevent Apple from crippling your GPU deliberately. The upgrade from 24 cores to 32 cores is reasonable at $200, while the comparable upgrade from 48 cores to 64 cores costs you $1000.
The customer paying $200 to go to 32 cores from 24 cores would likely have been happy with 24. Free margin.
The customer paying $1000 to go to 64 cores from 48 cores knows they need it and isn't sensitive to price. Free margin.
I think that Apple's GPU cores can only have three different GPU programs 'waiting'/concurrently executing on a single core: one fragment shader, one vertex function, and one compute kernel. Hence the 65,536 * 3 = 196,608 threads in-flight figure Apple quotes (probably due to each type of function having its own caches). I don't think you can have, for example, two compute kernels in a single GPU core. Latency is hidden in those instances just by 'sharing' the latency costs among all executed threads in the SIMD group.
That’s an interesting question actually. Apple has indicated that their GPUs are fully asynchronous, so I would be surprised if they even make a distinction between different kernel types. As to threads in flight, it depends on how many threads can fit into the register file. Would be interesting to test these things further, but I am not sure what the proper approach would be…


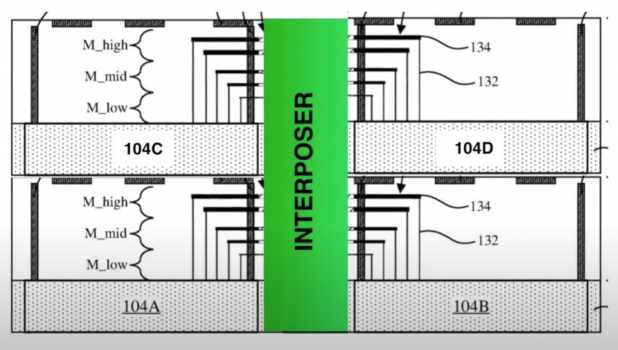
i wonder is this the way for the mac pro quad M1 max/duo M1 ultra ?!
It would have to be, but, again, the problem is that the M1 max, itself, only knows how to talk to one neighbor. It has no concept of addressing multiple neighbors. So even if you connect them, you would need some fancy logic to trick each max into thinking it is only talking to one neighbor, but figuring out how to send each piece of data to the right place. It can be done, but it would be a very complicated piece of silicon - apple might do it if they charge enough to make it worth their while, but it seems more likely they’d wait until M2.
side by side, i know but what about height interposer? its impossible right? i mean 2 ultra stack on top of each otherIt would have to be, but, again, the problem is that the M1 max, itself, only knows how to talk to one neighbor. It has no concept of addressing multiple neighbors. So even if you connect them, you would need some fancy logic to trick each max into thinking it is only talking to one neighbor, but figuring out how to send each piece of data to the right place. It can be done, but it would be a very complicated piece of silicon - apple might do it if they charge enough to make it worth their while, but it seems more likely they’d wait until M2.
Last edited:
I think he means that the M1 Max die itself can only talk to 1 other die because that is how the hardware is currently limited.side by side, i know but what about heigh interposer? its impossible right? i mean 2 ultra stack on top of each other
In the z-dimension? Nothing is impossible, but cooling is very difficult because silicon substrates do not transfer heat well laterally. In 1996 I published the following. Smarter people have come up with better solutions since then.side by side, i know but what about height interposer? its impossible right? i mean 2 ultra stack on top of each other
Also, it doesn’t solve the problem that there is only one “port” on the M1 Max for talking to another chip. So you’d need three chips stacked, with the middle chip playing traffic cop.
side by side, i know but what about height interposer? its impossible right? i mean 2 ultra stack on top of each other
Not only heat. A height "interposer" has problems because that would connect chip edges (as opposed to pad/bumps on the bottom/top ). Need to cut these dies out of the wafers. Now have to nano-join two cut edges (die on either side horizontally oriented ) to a top/bottom of an evidently rotated 90 degree piece of silicon.
Structural issues too if apply any torsion to that "house of cards" that is completely avoided if just join top/bottom only. Put that package on a bumpy truck ride and then see what you have.
Impractical, is probably closer than completely impossible. Make those in the millions in a timely fashion? I'd be surprised.
It is possible to have an interposer with through-vias, of course. It’s just expensive and difficult.Not only heat. A height "interposer" has problems because that would connect chip edges (as opposed to pad/bumps on the bottom/top ). Need to cut these dies out of the wafers. Now have to nano-join two cut edges (die on either side horizontally oriented ) to a top/bottom of an evidently rotated 90 degree piece of silicon.
Structural issues too if apply any torsion to that "house of cards" that is completely avoided if just join top/bottom only. Put that package on a bumpy truck ride and then see what you have.
Impractical, is probably closer than completely impossible. Make those in the millions in a timely fashion? I'd be surprised.
Sounds like something Apple could do for the Mac Pro since they sell so few…It is possible to have an interposer with through-vias, of course. It’s just expensive and difficult.
It is possible to have an interposer with through-vias, of course. It’s just expensive and difficult.
That is still "top to bottom" , not side to side. That diagram seems to be a view onto the edges rather than a "top down view" . 'drilling holes' in a middle of a chip is one thing structurally. Trying to 'glue' something to an edge of a chip is something else.
That is still "top to bottom" , not side to side. That diagram seems to be a view onto the edges rather than a "top down view" . 'drilling holes' in a middle of a chip is one thing structurally. Trying to 'glue' something to an edge of a chip is something else.
I have no idea what you’re saying. I commented about side-by-side. Someone asked about z-axis (“top to bottom”), and I responded about that.
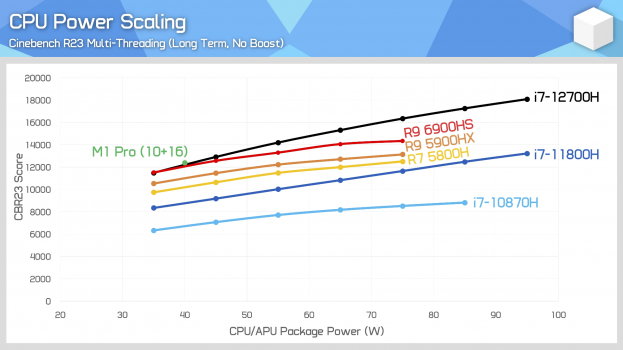
The only problem I can say for sure is that the M1 Pro results mixed up wall power and package power - ie in CB23 those are the right scores for the M1 Pro but according to Anandtech that 40W is a wall power measurement while the X-axis claims it is plotting package power. Again, according to Anandtech, the CB23 package for the M1 Pro is around 34W. I can't speak to the accuracy of their other measurements, but they don't seem unreasonable comparing a 14-core/20-thread 12700 to an 8-core/16-thread 6900HS or 10-core/10-thread M1 Pro in CB23.Can anyone confirm this power usage and performance? I tried to make some comments but they delete my comments right away! Something is suspicious. Even 12900HK does not perform well at 35~45W.
Last edited:
What if they set the power at 45W while they are using the wall power? Does it make any differences?The only problem I can say for sure is that the M1 Pro results mixed up wall power and package power - ie in CB23 those are the right scores for the M1 Pro but according to Anandtech that 40W is a wall power measurement while the X-axis claims it is plotting package power. Again, according to Anandtech, the CB23 package for the M1 Pro is around 34W. I can't speak to the accuracy of their other measurements, but they don't seem unreasonable comparing a 14-core/20-thread 12700 to an 8-core/16-thread 6900HS or 10-core/10-thread M1 Pro in CB23.
For the M1? No. Apple doesn’t allow for changing the wattage to the CPU. Theoretically it is possible and it would make a difference. Apple shows internally made graphs with their processors at different Watts (which ends at the factory shipped wattage). Apple's processors (according to Apple) are run "at the knee" of the perf/W curve such that additional amounts of voltage per core would begin to have diminishing returns. What is slightly interesting is that CB23 has fairly poor core utilization such that Apple's M1 Pro/Max is indeed typically at 40W package power/45W wall for a strenuous CPU load but it isn't when running CB23. The reasons why are delineated and debated in many, many posts in this thread.What if they set the power at 45W while they are using the wall power? Does it make any differences?
The Ultra with 20-cores/20-threads should have package power of about 70W and >20000 score.
? What? No, it doesn’t.
No it doesn’t.
Congratulations on finding a video that doesn’t prove your point I guess!
The fact that parallels needs to update its gui to show more than 8 cores doesn’t mean that programs have to be written in the the way they do for a graphics api. In parallels case it’s about LIMITING core use.
Last edited:
Why is M1 Ultra consider UMA and not NUMA?
Apple isn’t using the term UMA to refer to Uniform Memory Access. Apple’s UMA refers to unified memory architecture.
This is two different things.
So it’s unified memory architecture, but likely it is also non-uniform memory access.
Register on MacRumors! This sidebar will go away, and you'll see fewer ads.