Nice post thank you.
Obviously right now it is completely 100% impossible in OSX,
Why is it impossible? Some laptop user has already done this and posted his results too.
Anyone with a fast CUDA GPU and fast Mac Pro can see this for themselves.
1. Find the After Effects CUDA benchmark thread on this very forum.
2. Run it with a GPU in x16 lane, take screen shot of time.
3. Run it with same GPU in x4 lane, take another screenshot.
4. Compare times
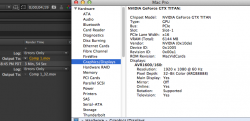
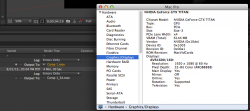
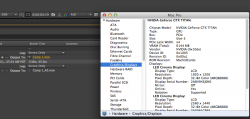
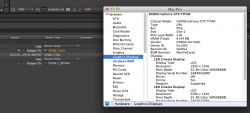
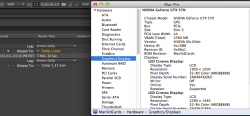
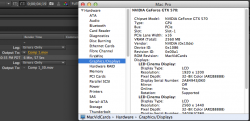
What I have found is that a GTX Titan goes from 240 seconds in a x16 lane to 270 seconds in a x4 lane. So it is being throttled by the loss of bandwidth, i.e. it is already "maxed out" trying to hold a single Titan.
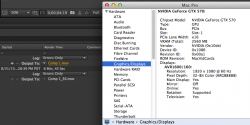
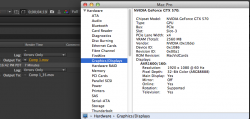
A GTX570 doesn't have as much CUDA power to begin with. It goes from 403 seconds to 420. That is 1 (ONE) GTX570 so it seems to ALMOST fit in the available bandwidth. Which means you will never be able to put MULTIPLE GPUs in an enclosure and not have them get throttled down by the paucity of bandwidth. Nor will you be able to daisy chain anything that requires data bandwidth on to that controller. (therefore, you lose 2 ports for data connections for each GPU)
One Titan loses 12.5% at x4, already out of bandwidth. Imagine 2 or three in an enclosure. Not going to be worth it. And this is with cards available today.
When you reduce the number of lanes from 16 to 4 you're also reducing the speed (frequency) at which data and commands can be sent and received so of course there will be some reduction. Tom's hardware showed about a 3% decrease on WinTel rendering CG frames in Blender (I think it was) and you show about 12% in OS X rendering video frames in AE, so now we have a range to go by here - which is good. Of course Video is going to be a worst case because typically frames are processed in a short period of time raising the Data-to-ProcessingTime ratio considerably. Because CUDA and OpenCL can work on one frame at a time and the work which gets carried out takes much more time than it takes to send and receive the commands and data - hundreds, thousands or even millions the time depending of the compute intensity and the kind of renderer (scan-line, bucket, etc.) and the work allocation method. The most efficient resource allocation method for GPU over TB/TB2 would probably be whole frame tasks where each GPU acts like an independent compute node sharing perhaps only system memory if/when needed.
During the card's compute time traffic to/from the card is extremely low as the card is using it's local cores to act on data in it's local memory. This leaves the buss open for commands and data to be sent to a second, third, and forth card all on the same connection - and I assume probably the contention won't become significant in most cases until 4 or 5 GPUs are operating on the same buss (connector). TB1 can do a single card with only a 3% reduction in render-times so it would be logical to assume two on a TB2 connection and taking into account the time-slices I'm talking about here more likely somewhere about 4 or 5 cards before the contention/saturation presents itself as anything close to devastating.
There are three controllers (six connections) so that's between 12 and 15 GPUs.
So let's assume a scenario where frames require 100 minutes to render with no GPGPU at all and a project size of 120 frames (200 total hours). With an internal PCIe v2 x16 GPGPU it's cut to 50min. That's a 50min. savings per frame. Now let's assume a radical 20% reduction per GPU with multiple GPUs daisy-chained on a single TB2 port (and not the 3% to 5% that Tom's hardware seems to imply over TB1) so each GPU spends about 60min. on a single frame - or reduces the total render time by about 40%. Someone check my math but I think that looks like:
CPU Only - No GPU (Total Render Time): 200 hours
1 PCIe 16x v2 GPU (Total Render Time): 100 hours
1 GPU on TB2 Port1 (Total render time): 120 hours
2 GPU on TB2 Port1 (Total render time): 72 hours
3 GPU on TB2 Port1 (Total render time): 43 hours
4 GPU on TB2 Port1 (Total render time): 26 hours
5 GPU on TB2 Port1 (Total render time): 15 hours
And let's say you have 12 GPUs working (4 GPUs on each of the three controllers) so now we can divide that 26 hours by three to get a total render time of 8.66 hours or let's just say with overhead and everything about 9 hours.
Now let's say each of those GPUs cost us a ridiculous $250 for used GTX 780's and $100 per TB2 --> PCIe adapter/enclosure six to twelve months from now (currently I see used GTX780's for $350) so that's about $4,200 all total. YAY we just sped up our renders by about ten times for only the cost of one workstation computer. That's a 10:1 price performance increase on our render-farm which now is comprised of a nMP and 12 little boxes instead of 8 or 10 full sized workstations. And keep in mind those figures are assuming each GPU is only able to contribute 80% of it's potential. For rendering 100min. frames I think it's more like Tom's hardware reported and there's only about a 3% reduction - due to latency and maybe a tad more due to traffic jams.
")
Will it actually work tho? I dunno. It should. Especially is someone like
Squidnet Software takes it up. But I don't see why woun't work right out of the box as is too. For every GPU you place on a TB port the ID and resource is communicated to the rendering engine just exactly like having two (or more) PC GPUs in a MacPro now. That works... so should this. For
most video rendering I assume the rule of diminishing returns will come into play a lot sooner than for CG frame renders in apps like Blender, C4d, LW3D, Maya, Xsi, and so on. Compositors like eyeon's Fusion some parts of FCP, Nuke, and so on will likely fair much better than video editors though.