I've said it before, but I think streaming is part of the future of gaming – not the only one. I mean if you play a competitive and fast paced game you want to have as low latency as possible. Also, already having displays capable of up to 360 Hz lowers latency even more. So, while I think streaming will get better and work well for many gaming scenarios, there are some aspects of gaming where streaming will have difficulties competing with a game rendered locally – also in the (not too distant at least…) future.I haven’t read all the 24 pages of this forum so it may have already been said but I think the future of gaming is streaming. As long as Apple doesn’t restrict the Mac like it does iOS, I could really see this taking off.
Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
The final blow for real gaming on the Mac, or the beginning of a new era?
- Thread starter Frankied22
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
I totally agree with you, I really should have said the future of Mac gaming is streaming.I've said it before, but I think streaming is part of the future of gaming – not the only one. I mean if you play a competitive and fast paced game you want to have as low latency as possible. Also, already having displays capable of up to 360 Hz lowers latency even more. So, while I think streaming will get better and work well for many gaming scenarios, there are some aspects of gaming where streaming will have difficulties competing with a game rendered locally – also in the (not too distant at least…) future.
Do you think that many high end publishers will be willing to spend a lot of money porting their games over to a different OS and platform? Especially given Apple's long history of providing tepid support of gaming. They're going to go where the money is, and with only a tiny niche (I believe) of apple's 10 percent market share seem focused on gaming, it doesn't make sense imo. There really isn't much opportunity to make money.
This has been the issue with gaming on the Mac from the very beginning, and ARM will not change it.
Yes, there will be games on ARM Macs, but don't expect the kind of top-rated titles you can find on other platforms. Independent game developers and small development shops may be curious enough to port some games over to Metal once in a while.
It takes PERFORMANCE to get gamers over. Nothing else matters. If you get 33 frames per second in Windows but only 32.999 frames on the Mac, THEY WILL GO TO WINDOWS.
If you want games on the Mac, you need to pray for performance that will simply blow everyone else out of the water. Then it can happen...but not without performance that is simply going to slaughter every other chip out there.
If you want games on the Mac, you need to pray for performance that will simply blow everyone else out of the water. Then it can happen...but not without performance that is simply going to slaughter every other chip out there.
Don't worry. Apple's Magical SOC's with 10 billion transistors will slaughter Nvidia's feckless wasteful 28 billion transistor GPU's like the 3080 because Apple is just so much more efficient... Those Nvidia engineers don't know what they're doing. /sIt takes PERFORMANCE to get gamers over. Nothing else matters. If you get 33 frames per second in Windows but only 32.999 frames on the Mac, THEY WILL GO TO WINDOWS.
If you want games on the Mac, you need to pray for performance that will simply blow everyone else out of the water. Then it can happen...but not without performance that is simply going to slaughter every other chip out there.
Seriously though Apple will not only need to at least be competitive with the competition's GPU's
They'll need to show they have a large enough installed base to convince devs to spend time/money developing for AS.
Last edited:
The install base argument works best including iOS/iPad devices. But for games like Control that will prove to be a problem because the game size is too large, and how the data files currently exist may not allow for easy downsizing.Don't worry. Apple's Magical SOC's with 10 billion transistors will slaughter Nvidia's feckless wasteful 28 billion transistor GPU's like the 3080 because Apple is just so much more efficient... Those Nvidia engineers don't know what they're doing. /s
Seriously though Apple will not only need to at least be competitive with the competition's GPU's
They'll need to show they have a large enough installed base to convince devs to spend time/money developing for AS.
If it brings the best iOS games to the Mac I’d be very happy indeed. Playing marvel strike force on my iPad Pro , the graphics are impressive to say the least ! Good as my PS4 pro tbh .
Not sure the Switch is so successful then.It takes PERFORMANCE to get gamers over.
the A14 has 11.9 Billion transisors, and that's just a mobile chip, used for mid range iPads and iPhones.Don't worry. Apple's Magical SOC's with 10 billion transistors will slaughter Nvidia's feckless wasteful 28 billion transistor GPU's like the 3080 because Apple is just so much more efficient... Those Nvidia engineers don't know what they're doing. /s
Seriously though Apple will not only need to at least be competitive with the competition's GPU's
They'll need to show they have a large enough installed base to convince devs to spend time/money developing for AS.
the A12Z is a 2 year old SoC with 10 billion transistors, that's just used for the iPad Pro.
the RTX 3080 is a DESKTOP class GPU has 28 billion transistors.
unless Apple themselves start making AAA titles for Apple Arcade...This has been the issue with gaming on the Mac from the very beginning, and ARM will not change it.
Yes, there will be games on ARM Macs, but don't expect the kind of top-rated titles you can find on other platforms. Independent game developers and small development shops may be curious enough to port some games over to Metal once in a while.
Don't worry. Apple's Magical SOC's with 10 billion transistors will slaughter Nvidia's feckless wasteful 28 billion transistor GPU's like the 3080 because Apple is just so much more efficient... Those Nvidia engineers don't know what they're doing. /s
NVidia's GPUs actually are wasteful compared to Apple's, though. This is for very well understood reasons known to the whole industry - they're immediate mode and Apple's GPUs are tile-based deferred. Immediate mode GPUs waste a lot of their computational power and memory bandwidth doing work which gets thrown away (it's hard for immediate mode tech to avoid rasterizing occluded objects).
This isn't because Nvidia engineers don't know what they're doing, it's because the momentum built by designing so many generations of immediate mode rasterizers, and being rewarded for it, compels Nvidia management to always tell their engineers to keep iterating on what the company knows how to do. It's a big risk to upend everything and switch to a brand new (to Nvidia) tech. Especially when you're Nvidia, and you've pivoted in a big way to GPGPU, where the inefficiency of immediate mode graphics doesn't matter so much because the excess compute power turns into an advantage. GPGPU makes it possible for Nvidia to sell close relatives of their big PC GPUs for $5000 apiece, so... you do the math. They're not likely to rock their own boat a whole lot.
As with many other things, the 3D rasterization tech the PC market picked as the winner was the one which was ready the earliest and reasonably good, not necessarily the best one. And once the winner of such a fight is moving lots of units, it's hard for a better technology to get a fair shake, because the guys who are selling high volume get to spend a lot more on near-perfect execution of their flawed tech, and that means it can match or exceed the performance of imperfectly executed (because lower resources) better tech. (See also: Intel.)
Imagination was the main company trying to do TBDR in the early PC 3D graphics market, and they failed precisely because they weren't mature enough when Nvidia had a really good product, but they didn't go away - they kept pushing their technology where they had a compelling advantage, mobile. TBDR is just way more power- and transistor-efficient than immediate, so it was a great match for mobile. And now, Apple's going to bring TBDR GPUs back to the desktop. Should be fun to find out where it shakes out.
Everything we’ve heard so far about Apple silicon sounds great in terms of performance but one area that I am still very curious about is the gpu and gaming. A lot of people are saying this will be the final nail in the coffin for any chance to have high end gaming on the Mac but I’m not so sure. Apple already has been making some pretty impressive gpus on their A chips in both the iPhone and iPad. There are games on the iPad that I would say are approaching console level quality (not newest consoles of course) and lets not forget that it is pushing a 120hz high resolution screen.
I have a feeling that we are going to be quite impressed with the graphics on the new Mac chips since they can increase the size and provide more cooling to it for better thermals. I could see a future 4-5 years from now where, as long as devs also make their games compatible with Apple silicon, we could finally have high end gaming on the Mac.
We had a pretty good 3 years of Mac gaming from 2009-2012. This was back when NVIDIA was in most of the lineup and developers didn't have the retina display and HiDPI to contend with. Also, Apple wasn't releasing entire new OSes EVERY FREAKIN' YEAR causing developers to constantly redo everything in order to maintain compatibility and parity with the new OSes in order to survive. Add to that the sad fact that unless a game is constantly maintained and updated (which most single-player games aren't), it won't survive Apple's regular transitions and deprecations of underlying technologies.
Add to that, the already messy process of porting from x86 Windows to x86 macOS, and just how much messier it gets when going from x86 Windows to not just ARM macOS, but Apple Silicon macOS and you're already removing incentive for many developers to even try.
The GPU differences are stark and not insubstantial. I do believe that Apple Silicon iGPUs will deliver the goods and will outperform what we have on current Intel Macs by a fair margin so long as code is optimized for Apple's stack. However, I think the task of porting games to Apple's GPUs will be seen by AAA title developers (even Aspyr and Feral) as being not worth it. You're already seeing a mass shift on Aspyr to managing Linux ports rather than pushing out Mac ports. That's a REALLY bad sign for gaming on the Mac. Furthermore, you have the Apple TV, which has console caliber graphics capabilities already on Apple Silicon, and you don't see an influx of games. Other than the nonsense around Apple's cut from App Store purchases, there's no other reason why the Apple TV platform can't be competing with the likes of Nintendo, Microsoft, and Sony.
That all being said, with computers like the current 27" iMac and the 16" MacBook Pro, there's no reason you can't do impressive high end gaming on those systems today other than the fact that developing for macOS isn't as easy or as profitable as doing so for Windows. The hardware isn't the problem as much as developing for macOS is; at least as far as Intel Macs are concerned. On the Apple Silicon side of things, the different hardware only compounds the issues.
One ray of hope, however, are recent Metal programming tools that Apple released for Windows 10. But I wouldn't hold my breath. Apple really needs to make inroads with console game and PC game developers to make it less developer-hostile.
Where did you get all of the above info from? I'm genuinely curious.NVidia's GPUs actually are wasteful compared to Apple's, though. This is for very well understood reasons known to the whole industry - they're immediate mode and Apple's GPUs are tile-based deferred. Immediate mode GPUs waste a lot of their computational power and memory bandwidth doing work which gets thrown away (it's hard for immediate mode tech to avoid rasterizing occluded objects).
This isn't because Nvidia engineers don't know what they're doing, it's because the momentum built by designing so many generations of immediate mode rasterizers, and being rewarded for it, compels Nvidia management to always tell their engineers to keep iterating on what the company knows how to do. It's a big risk to upend everything and switch to a brand new (to Nvidia) tech. Especially when you're Nvidia, and you've pivoted in a big way to GPGPU, where the inefficiency of immediate mode graphics doesn't matter so much because the excess compute power turns into an advantage. GPGPU makes it possible for Nvidia to sell close relatives of their big PC GPUs for $5000 apiece, so... you do the math. They're not likely to rock their own boat a whole lot.
As with many other things, the 3D rasterization tech the PC market picked as the winner was the one which was ready the earliest and reasonably good, not necessarily the best one. And once the winner of such a fight is moving lots of units, it's hard for a better technology to get a fair shake, because the guys who are selling high volume get to spend a lot more on near-perfect execution of their flawed tech, and that means it can match or exceed the performance of imperfectly executed (because lower resources) better tech. (See also: Intel.)
Imagination was the main company trying to do TBDR in the early PC 3D graphics market, and they failed precisely because they weren't mature enough when Nvidia had a really good product, but they didn't go away - they kept pushing their technology where they had a compelling advantage, mobile. TBDR is just way more power- and transistor-efficient than immediate, so it was a great match for mobile. And now, Apple's going to bring TBDR GPUs back to the desktop. Should be fun to find out where it shakes out.
My limited research on this subject indicates that it's highly unlikely that desktop GPU manufacturers are leaving any performance on the table by not using TBDR. They've already incorporated some of the better parts of the "tile based" portion of rendering into their chips, and the deferred rendering part incurs both latency and increased load vs immediate rendering on more complex scenes. Most of that does not jive with what you are saying. There's really no evidence I can find to indicate that nVidia is being lazy with their GPU's or that immediate mode rendering isn't the right choice for the desktop.
They've already incorporated some of the better parts of the "tile based" portion of rendering into their chips, and the deferred rendering part incurs both latency and increased load vs immediate rendering on more complex scenes.
Why would TBDR increase latency? It’s literally about doing less work altogether. And the way Apple implements it gives the programmer direct control over the on-chip cache memory allowing to implement many rendering algorithms more efficiently
Most of that does not jive with what you are saying. There's really no evidence I can find to indicate that nVidia is being lazy with their GPU's or that immediate mode rendering isn't the right choice for the desktop.
Nvidia is definitely not being lazy with their GPUs (as a tech enthusiast I’d rather use the term boring) and forward rendering definitely works very well on desktop - there is a good reason why all desktop GPUs are forward renderers. Desktop can afford to be wasteful after all.
At the same time, while current GPUs are the fastest yet, they are also the most power hungry ones in history. For how long can we keep this up? What will the Nvidia 400 series ne - 500W GPU? They are already using every trick in the book to squeeze as much of the GPU as possible... and then there are new technologies such as ray tracing which clash with the concept of forward rendering.
I think that Apple has tremendous potential in the GPU department exactly because of the TBDR approach. I wrote some more on that in a separate thread, in case you are interested: https://forums.macrumors.com/thread...tbdr-rt-and-the-benefit-of-wide-alus.2258523/
It’s not doing less work in all situations. It’s trading one type of work for another to save on memory bandwidth. All the geometry has to be sorted prior to rendering each tile.Why would TBDR increase latency? It’s literally about doing less work altogether. And the way Apple implements it gives the programmer direct control over the on-chip cache memory allowing to implement many rendering algorithms more efficiently
Nvidia is definitely not being lazy with their GPUs (as a tech enthusiast I’d rather use the term boring) and forward rendering definitely works very well on desktop - there is a good reason why all desktop GPUs are forward renderers. Desktop can afford to be wasteful after all.
At the same time, while current GPUs are the fastest yet, they are also the most power hungry ones in history. For how long can we keep this up? What will the Nvidia 400 series ne - 500W GPU? They are already using every trick in the book to squeeze as much of the GPU as possible... and then there are new technologies such as ray tracing which clash with the concept of forward rendering.
I think that Apple has tremendous potential in the GPU department exactly because of the TBDR approach. I wrote some more on that in a separate thread, in case you are interested: https://forums.macrumors.com/thread...tbdr-rt-and-the-benefit-of-wide-alus.2258523/
It’s not doing less work in all situations. It’s trading one type of work for another to save on memory bandwidth. All the geometry has to be sorted prior to rendering each tile.
I understand where you re coming from, but that's a common misconception about how modern TBDR works. You would be absolutely correct if the GPU had to actually sort the geometry... but that's not how they do it. The beauty of the entire system is that they simply use forward rendering for the sorting pass, just like the desktop GPUs. But instead of immediately passing the rasterized pixels to the pixel shader, a TDBR renderer stores the visibility information (primitive id etc.) in a special buffer. After all primitives are rasterized to this buffer, you end up with information about every visible pixel in a tile. That's what they mean when they say that the geometry is "sorted". A TBDR GPU uses this visibility buffer to invoke the pixel shader, meaning that the expensive shading is invoked only once per each visible pixel (hence deferred renderer: pixels are not shaded immediately, but only after all geometry has been processed). You can read more about it here (I am fairly sure that Apple has inherited this approach from their PowerVR heritage, maybe with some minor optimizations).
So to address your concern, no, a TBDR GPU does not need to do any extra work to sort geometry, the entire sorting phase is done via rasterization, just like in any forward rendering GPU. A TBDR GPU does need to do binning/tiling, but a) it's cheap and b) modern forward renderers do it as well.
Now, it should be obvious that I am a fan of the TBDR architecture, but since we want to be at least a bit unbiased, let me also mention some disadvantages of the TBDR (at least what comes to the top of my head). First of all, if you have a lot of translucent/transparent geometry, TBDR can't work it's efficiency magic and it just becomes an over-engineered forward renderer. Since all currently used TBDR GPUs are ultra-mobile architectures that don't have a lot of memory bandwidth, the performance hit tends to be noticeable. Second, TBDR has some problems with on-GPU geometry generation. TBDR requires all geometry to be processed before it can start shading, so some modern approaches like mesh shading (which generate and immediately rasterize transient geometry on the GPU) are not a good fit for it. It doesn't mean that you can't do GPU-driven geometry generation — you definitely can and should — it just requires a slightly different paradigm. Third, TBDR GPUs are much more complex architectures hardware-wise (especially in the front-end) and they require some extra software effort if you want to get most out of them.
Other disadvantages I'm reading about ... deferring the shading is inherently non-parallel. You are deferring/delaying work that could be finished immediately to save on memory bandwidth or shader resources. There are a lot of reasons why this frequently won't be optimal.I understand where you re coming from, but that's a common misconception about how modern TBDR works. You would be absolutely correct if the GPU had to actually sort the geometry... but that's not how they do it. The beauty of the entire system is that they simply use forward rendering for the sorting pass, just like the desktop GPUs. But instead of immediately passing the rasterized pixels to the pixel shader, a TDBR renderer stores the visibility information (primitive id etc.) in a special buffer. After all primitives are rasterized to this buffer, you end up with information about every visible pixel in a tile. That's what they mean when they say that the geometry is "sorted". A TBDR GPU uses this visibility buffer to invoke the pixel shader, meaning that the expensive shading is invoked only once per each visible pixel (hence deferred renderer: pixels are not shaded immediately, but only after all geometry has been processed). You can read more about it here (I am fairly sure that Apple has inherited this approach from their PowerVR heritage, maybe with some minor optimizations).
So to address your concern, no, a TBDR GPU does not need to do any extra work to sort geometry, the entire sorting phase is done via rasterization, just like in any forward rendering GPU. A TBDR GPU does need to do binning/tiling, but a) it's cheap and b) modern forward renderers do it as well.
Now, it should be obvious that I am a fan of the TBDR architecture, but since we want to be at least a bit unbiased, let me also mention some disadvantages of the TBDR (at least what comes to the top of my head). First of all, if you have a lot of translucent/transparent geometry, TBDR can't work it's efficiency magic and it just becomes an over-engineered forward renderer. Since all currently used TBDR GPUs are ultra-mobile architectures that don't have a lot of memory bandwidth, the performance hit tends to be noticeable. Second, TBDR has some problems with on-GPU geometry generation. TBDR requires all geometry to be processed before it can start shading, so some modern approaches like mesh shading (which generate and immediately rasterize transient geometry on the GPU) are not a good fit for it. It doesn't mean that you can't do GPU-driven geometry generation — you definitely can and should — it just requires a slightly different paradigm. Third, TBDR GPUs are much more complex architectures hardware-wise (especially in the front-end) and they require some extra software effort if you want to get most out of them.
Triangles crossing tiles are drawn multiple times.
Some rendering techniques/effects work with the entire frame and aren't compatible with tile based rendering approaches.
How well does TBDR deal with particle effects?
As an aside, before the "breakup" you could see that the iOS (mobile) version of Fortnite was missing a lot of subtle things, like waving grass and trees, and some particle effects. Is this due to the transparency issue?
As an aside, before the "breakup" you could see that the iOS (mobile) version of Fortnite was missing a lot of subtle things, like waving grass and trees, and some particle effects. Is this due to the transparency issue?
You do get free (MS)AA though!Other disadvantages I'm reading about ... deferring the shading is inherently non-parallel. You are deferring/delaying work that could be finished immediately to save on memory bandwidth or shader resources. There are a lot of reasons why this frequently won't be optimal.
Triangles crossing tiles are drawn multiple times.
Some rendering techniques/effects work with the entire frame and aren't compatible with tile based rendering approaches.
Other disadvantages I'm reading about ... deferring the shading is inherently non-parallel. You are deferring/delaying work that could be finished immediately to save on memory bandwidth or shader resources. There are a lot of reasons why this frequently won't be optimal.
This doesn't make much sense to me. Shading in TBDR is done by invoking a shaders over a grid of rasterized pixels. Shading in IR is done by invoking shaders... over a grid of rasterized pixels. If anything, TBDR has more opportunities for parallel shader execution because the work item grid is always regular, while an IR runs into issues with SIMD units occupation when triangles are small or when rasterizing edges.
Triangles crossing tiles are drawn multiple times.
This is not correct. That would introduce visual artifacts anyway. If a triangle spans multiple tiles, it will obviously be rasterized in all those tiles, but tiles don't overlap.
Some rendering techniques/effects work with the entire frame and aren't compatible with tile based rendering approaches.
If you don't have any overdraw, TBDR doesn't really have any effect, yes. If you are just drawing flat non-overlapping geometry over the frame, the TBDR renderer will simply "degrade" to an immediate mode renderer. Depending on what you want to do, TBDR can still be more efficient — with memoryless render targets and control over tile memory layouts many techniques can be implemented in a fashion that eliminates the need for off-chip memory access. Now, if you need to sample data from the frame at random locations, yeah, TBDR won't help you at all, but neither would forward rendering.
This is not my deep area of expertise, so you'll have to bear with me if I'm getting the concepts/terminology wrong. But it's a different level of parallelism, isn't it? Work begins "immediately" in an immediate mode renderer, whereas in order to receive the benefits of tile based rendering, you must wait until the geometry in a tile is processed. Waiting to reduce the usage of other resources has its own kind of cost to performance. This makes sense to me as a drawback ... I see it all the time in high performance parallel systems. People try to introduce "smarts" and it ends up bottlenecking scalability.This doesn't make much sense to me. Shading in TBDR is done by invoking a shaders over a grid of rasterized pixels. Shading in IR is done by invoking shaders... over a grid of rasterized pixels. If anything, TBDR has more opportunities for parallel shader execution because the work item grid is always regular, while an IR runs into issues with SIMD units occupation when triangles are small or when rasterizing edges.
Mobile class GPU's are sharing memory bandwidth with the system to begin with, and on top of that desktop GPU's are using dedicated memory with over 10x the bandwidth. The bottlenecks simply aren't the same ... deferring work to save memory bandwidth isn't going to take the same priority in a higher performance system.
OK, maybe I didn't mean "drawn" multiple times, but much of the processing work is done for a large triangle redundantly for each tile, on top of having to calculate the tiles each triangle falls in. I'm quite certain this drawback is correct. Having to process the same triangle multiple times when it is large enough to cross multiple tiles is cited in multiple places as a drawback of tile based rendering.This is not correct. That would introduce visual artifacts anyway. If a triangle spans multiple tiles, it will obviously be rasterized in all those tiles, but tiles don't overlap.
One citation: https://graphics.stanford.edu/papers/bucket_render/paper_all.pdf
Well, I assume TBDR has a cost in silicon compared to a simpler approach, so it's not really "free", is it?If you don't have any overdraw, TBDR doesn't really have any effect, yes. If you are just drawing flat non-overlapping geometry over the frame, the TBDR renderer will simply "degrade" to an immediate mode renderer. Depending on what you want to do, TBDR can still be more efficient — with memoryless render targets and control over tile memory layouts many techniques can be implemented in a fashion that eliminates the need for off-chip memory access. Now, if you need to sample data from the frame at random locations, yeah, TBDR won't help you at all, but neither would forward rendering.
This is not my deep area of expertise, so you'll have to bear with me if I'm getting the concepts/terminology wrong. But it's a different level of parallelism, isn't it? Work begins "immediately" in an immediate mode renderer, whereas in order to receive the benefits of tile based rendering, you must wait until the geometry in a tile is processed. Waiting to reduce the usage of other resources has its own kind of cost to performance. This makes sense to me as a drawback ... I see it all the time in high performance parallel systems. People try to introduce "smarts" and it ends up bottlenecking scalability.
Ah, I think I understand what you mean. You are saying that in a TBDR model the shader invocation has to wait until all the geometry in a tile has been processed. I wouldn't use the term parallelism here, it's more about latency. Anyway, this would be a cause for concern if you had shaders waiting to do pixel work... but this is a unified shader architecture. There is always work to do. You have compute shaders, vertex shaders, other tiles to process... one of the strong points of modern GPUs is automatic work balancing and latency hiding.
What is really relevant her tis the time it takes to draw a tile. A TBDR will invoke the pixel shader later, but it will only need to one "large" pixel shader dispatch. An IR will dispatch "small" pixel shader tasks continuously (see below for more details), but it will end up processing many more pixels. If you have a decent amount of overdraw, TBDR will end up doing much less work overall. And even more importantly, it will significantly reduce cache trashing and trips to the off-chip memory.
Mobile class GPU's are sharing memory bandwidth with the system to begin with, and on top of that desktop GPU's are using dedicated memory with over 10x the bandwidth. The bottlenecks simply aren't the same ... deferring work to save memory bandwidth isn't going to take the same priority in a higher performance system.
Exactly! We see TBDR in mobile space because it's the only way to get reasonable performance out of bandwidth and energy-starved environment. We don't see it in the desktop space because IR are simpler devices and one can afford to be a bit wasteful in the desktop space anyway.
OK, maybe I didn't mean "drawn" multiple times, but much of the processing work is done for a large triangle redundantly for each tile, on top of having to calculate the tiles each triangle falls in. I'm quite certain this drawback is correct. Having to process the same triangle multiple times when it is large enough to cross multiple tiles is cited in multiple places as a drawback of tile based rendering.
One citation: https://graphics.stanford.edu/papers/bucket_render/paper_all.pdf
One problem with theoretical computer science is that it can be 100% correct and yet quite useless in real world
") Also, the paper you are quoting is from 1998... a lot of things changed since then. The authors are obviously correct that there is a per-triangle-per-tile setup cost — you need to find the tiles that the triangle intersects and store that information — but in practical terms this cost is zero or at least very very small. I have no idea how tiling is done in hardware, but a naive algorithm that comes to my mind is simply using a rasterizer to "draw" the triangle to a grid where a tile is represented by exactly one pixel. Let us consider the worst case scenario. A full-screen triangle at 5K (5120x2880) resolution will touch every single tile. At 32x32 tile size, this is a 160x90 tile grid or 14400 tiles to be marked. Sounds like a lot, right? But when we actually start rasterizing the triangle properly, which we need to do anyway, it will generate whopping 14745600 pixels — that is the amount of work our rasterizer needs to run through anyway! It's an overhead of 0.1%, on an operation that is already really really cheap. For smaller triangles, the overhead will be much lower, as they will touch fewer tiles. Not to mention that you can do other stuff with tiling, like running multiple rasterizers in parallel for different tiles. And that this is the overhead using the most naive approach to tiling — I am sure that experienced engineers who work on it for years were able to come up with a better idea than an amateur like me could do in a minute
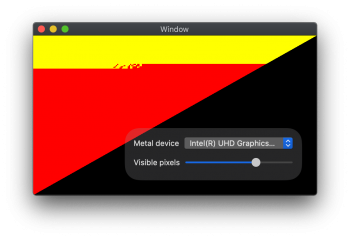
Also, the paper you are quoting is from 1998... a lot of things changed since then. The authors are obviously correct that there is a per-triangle-per-tile setup cost — you need to find the tiles that the triangle intersects and store that information — but in practical terms this cost is zero or at least very very small. I have no idea how tiling is done in hardware, but a naive algorithm that comes to my mind is simply using a rasterizer to "draw" the triangle to a grid where a tile is represented by exactly one pixel. Let us consider the worst case scenario. A full-screen triangle at 5K (5120x2880) resolution will touch every single tile. At 32x32 tile size, this is a 160x90 tile grid or 14400 tiles to be marked. Sounds like a lot, right? But when we actually start rasterizing the triangle properly, which we need to do anyway, it will generate whopping 14745600 pixels — that is the amount of work our rasterizer needs to run through anyway! It's an overhead of 0.1%, on an operation that is already really really cheap. For smaller triangles, the overhead will be much lower, as they will touch fewer tiles. Not to mention that you can do other stuff with tiling, like running multiple rasterizers in parallel for different tiles. And that this is the overhead using the most naive approach to tiling — I am sure that experienced engineers who work on it for years were able to come up with a better idea than an amateur like me could do in a minute But even disregarding all that — modern desktop GPUs already use tiling! So it must be worth it for them. Here is a screenshot from a tool I wrote to study rasterization patterns on Macs:
Here, I am drawing two large overlapping triangles: yellow over red, while limiting the amount of pixels shaded, on a MacBook Pro with an AMD Navi GPU. As you can see, the GPU tiles the screen into large rectangular areas which are rasterized in tile order (left to right, top to bottom). Inside the large tiles, you get smaller square block artifacts. These blocks correspond to the invoked pixel shader groups: since Navi SIMD units are 32-wide units, it needs to receive work in batches of 32 items to achieve good hardware utilization. The blocks itself are 8x8 pixels, so once the rasterizer has output a 8x8 (64 pixels in total) pixel block, the pixel shader is executed. The tiling capability of Navi is fairly limited, once I go over a certain number of triangles (I think it's about 512, but I need to verify it), it resets. I am sure that details are much more complex, but this gives us a general idea how this stuff works. Nvidia is similar (can't test it since I don't have one, but I saw results from other people), just with different tile and block sizes. Intel (at least in the Skylake gen) does not use tiling (see the other screenshot I have attached), and it also uses different SIMD dispatch blocks (4x4 pixels — which makes sense given that fact that Intel Gen uses 4-wide SIMD).
As you can see, tiling must be cheap and beneficial enough so that big houses like Nvidia and AMD use it as well. But while they use tiling rendering, this is not deferred rendering: you can see the bottom red triangle drawn before the yellow triangle paints it over. Each pixel gets shaded twice. On a TBDR GPU (iPad, iPhone etc.) you won't ever see any red pixels, because the pixel shader is never called for the red triangle.
Well, I assume TBDR has a cost in silicon compared to a simpler approach, so it's not really "free", is it?
Definitely not free
TBDR is a much more complex design, it needs more meticulously designed fixed function hardware, and there are a lot of details that I can only assume are extremely difficult to get right. That's why there is only one company that really gets TBDR done right, and it's Imagination Technologies, who has been researching and designing these GPUs for the last 20+ years. Apple GPUs are based on top of Imagination IP, with Apple possibly refining the architecture further.Attachments
Last edited:
Whatever Nvidia is doing, the Apple A12Z appears much more efficient that an Nvidia GPU. I
BTW, should we say "direct rendering" or "forward rendering"? I think Apple opposes TBDR to "Direct Renderer".
Are you saying that a TBDR architecture is better suited for the inclusion of ray tracing in real time games?and then there are new technologies such as ray tracing which clash with the concept of forward rendering.
BTW, should we say "direct rendering" or "forward rendering"? I think Apple opposes TBDR to "Direct Renderer".
Whatever Nvidia is doing, the Apple A12Z appears much more efficient that an Nvidia GPU. I
Are you saying that a TBDR architecture is better suited for the inclusion of ray tracing in real time games?
BTW, should we say "direct rendering" or "forward rendering"? I think Apple opposes TBDR to "Direct Renderer".
A Toyota Prius is more efficient than a Bugatti Chiron, but it can't hit 300mph and the Bugatti can. Efficiency isn't everything.
Which is interesting since there are 0 games (as far as we know) on iOS that is using Ray Traced GI or Reflections. There are 2 games that support it on other platforms (Fortnite and MineCraft) but those features haven't trickled down to mobile (and in the case of Fortnite, won't ever).Whatever Nvidia is doing, the Apple A12Z appears much more efficient that an Nvidia GPU. I
Are you saying that a TBDR architecture is better suited for the inclusion of ray tracing in real time games?
BTW, should we say "direct rendering" or "forward rendering"? I think Apple opposes TBDR to "Direct Renderer".
Register on MacRumors! This sidebar will go away, and you'll see fewer ads.