Your premise is broken. RISC has frequently outperformed x86 in the past. Those RISC machines never took over the world simply because they didn’t run consumer/x86 versions of Windows. The DEC Alpha blew away contemporaneous Intel products. So did the Exponential PowerPC...
In the late 90s I personally ran lots of side-by-side performance tests between various Alpha, MIPS and Pentium Pro workstations. On commercial software dominated by integer code, I never saw a marked RISC performance advantage. It is true the RISC machines often had better floating point performance, but that was a small subset of all use cases.
On the server side (where desktop/consumer software has little impact), both current and historical performance numbers are available for transaction processing. Essentially all current TPC-E results are dominated by x86 machines: http://www.tpc.org/tpce/results/tpce_results5.asp
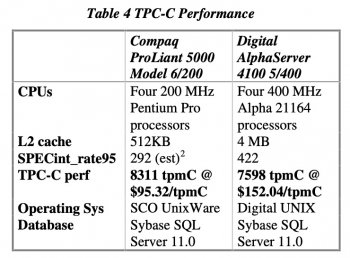
The older TPC-C benchmark dating back to around 1999 has some competitive RISC servers, but even back then x86 held many of the top slots and typically at a vastly cheaper capital cost per transaction:
TPC-C All Results
The Transaction Processing Performance Council (TPC) defines Transaction Processing and Database Benchmarks and delivers trusted results to the industry.
www.tpc.org
JMacHack may be correct -- The Apple SoC has a lot of heterogeneous accelerators, which if leveraged by proper software might explain the advantage, at least for certain workloads. However it doesn't explain a straight-up benchmark like GeekBench or Linpack looking roughly competitive on an A12Z vs an i7-7700K Kaby Lake CPU.
A useful number would be transistors per core between late-generation x86 and Apple Silicon cores. I don't think that has ever been revealed but it's obtainable by taking die shots of a decapped chip. It is generally assumed that Ax CPUs consume less transistor budget per core, but we don't really know. If it is significantly less, that would enable more cores per die at approx. similar fabrication costs. It's interesting the first Apple Silicon machine is rumored to be a 13" MacBook Pro with 12 cores.
Of course you also need good single-thread performance, and traditionally that has been costly from a transistor budget and power standpoint. It's conceivable something about the Ax architecture facilitates improving superscalar performance at less cost per increment than x86, but if so that hasn't been borne out by POWER9 or the 48-core ARM/Fujitsu A64FX. They are competitive with high-end Xeon & AMD but both burn huge amounts of power : https://en.wikipedia.org/wiki/Fujitsu_A64FX