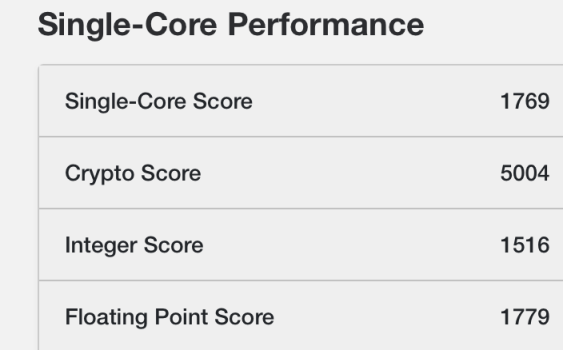
I think it needs to be said explicitly for all the CB23 pushers: Cinebench uses hand-optimized x86 SIMD code. Instead of actually rewriting that for Arm, Cinebench's Arm port relies on a library which autotranslates every x86 SIMD instruction to an equivalent sequence of NEON SIMD instructions.
This is a very quick and dirty way to stand up a port with okay performance. It is extremely far from being a true native port that is well optimized for Arm. If the situation were reversed, you'd be screaming to high heavens that x86 CPUs were being treated unfairly in the comparison - and you'd be right!
Stop using CB23 for crossplatform comparisons between x86 and Apple Silicon. It's simply pointless. Unless you like trolling, I guess.
So who on the Cinebench team do we gotta talk to in order to get them to properly optimize Cinebench for Apple Silicon?
It’s in their best interest to take the time to do this, because then Cinebench could be used as the gold standard CPU benchmark for any system without any asterisks.
 rimatelabs.com neon
rimatelabs.com neon