Zen4 will be 2 years after Zen3. I don't think that's a reasonable cadence. That's slow compared to Intel's current roadmap.
I wouldn't use the word "reorganized" to describe A14 to A15. That would imply that they use the same cores but just organized differently. We see from Anandtech's breakdown of the A15 that the cores did in fact change, especially the efficiency cores which received a massive upgrade.
Raptor Lake is expected to have upgrades to ADL cores.
Zen 3+ desktop isn't a refresh. It's a single SKU (5800X) that has 3D cache glued on. It's targeted at gaming only as its clock speeds needed to decrease in order to accommodate extra heat. Perhaps you're confusing it with AMD's 6nm mobile Zen3 refresh?
You don't need DDR5 for Alder Lake. It can work with DDR4. In some applications, DDR4 was faster than DDR5 and vice versa.
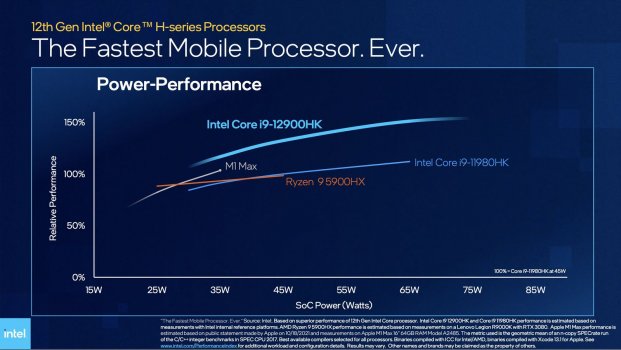
This isn't an issue. This is a design choice. Golden Cove beats Zen3 in ST by nearly 20%. That's 1-2 generation difference. This is why it's big.
Again, this is a design decision. ADL is primarily aimed at laptops but works well on desktop too. On desktop, the little cores do indeed massively boosts MT in a smart way. I don't see anything wrong with the design vs AMD when the results speak for themselves.
I don't think they were trying to explain it to me. I'm well aware of ADL's power ratings since I invest in semiconductor companies and follow every product closely. I'm also typing on an M1 Pro laptop right now with an A15 iPhone 13 next to me.
@Andropov and
@leman were a bit confused. They were trying to say that ADL's little cores aren't designed to be as low power as little cores inside Apple Silicon. I was merely trying to point out that ADL was designed to compete against AMD, and to improve efficiency on laptops. I think ADL accomplishes both. It does not matter if ADL's little cores aren't "traditional" little cores.
The computer world has moved to big.Little in virtually every category except servers. big.Little makes too much sense for phones, laptops, and desktops. It's not an advantage for AMD that they don't a big.Little design right now.
I don't think people are saying AMD is lacking progress. I think people are saying that ADL is hugely impressive in the x86 world and comfortably beats AMD's products on desktop and laptops at the moment.
I expect Zen4 to beat Raptor Lake in perf/watt in Q4 of this year but I expect Meteor Lake to surpass Zen4 two quarters later. If Zen5 takes two years to come out like Zen3 to Zen4, I think AMD will be in huge trouble.

www.pcworld.com