thenewperson
macrumors 65816
Ah, sorry about that, I was certain they include the query in the link. At any rate, you can use the following query —
Code:FP:(neural) AND ALLNAMES:(Apple)
Some of that was converted to emoji 🫢
Ah, sorry about that, I was certain they include the query in the link. At any rate, you can use the following query —
Code:FP:(neural) AND ALLNAMES:(Apple)
The original discrepancy was/is between the M3 number Apple used, and the A17 number. This flew in the face of everything that had come before, from the introduction of the ANE in 2017, and then A12/A12X+; A14/M1+; and A15/M2+ -- each of those generations had the same ANE in the base iPhone and the iPad/Mac variants.This is one of these claims that is endlessly repeated on the internet. But repetition doesn't make it true.
I keep waiting for the evidence of this supposed 2x INT8 throughput and I never see it. [...] F16 and I8 results mostly run on ANE, and we usually see very little difference either between F16 and I8, or not much beyond the 10% or so from usual tweaks and higher GHz from A16 to A17. There's a lot of variation, sometimes explicable, usually not, but nothing that suggests a pattern of ANE I8 runs at 2x ANE F16. Certainly nothing that supports these claims.
I continue to hold that the most likely meaning of Apple's claim of doubled TOPs in A17 is basically a redefinition of TOPs in reaction to other companies, not redefining I8 vs F16 but redefining what counts as an "op" to include who knows what other elements that the ANE can perform in parallel with FMAC's - maybe activations?, maybe pooling and other planar ops?, maybe applying some standardized scaling to the timing of some standardized benchmark?

| iPhone 12 Pro | CPU_AND_NE | SPLIT_EINSUM | 116* | 0.50 |
| iPhone 13 Pro Max | CPU_AND_NE | SPLIT_EINSUM | 86* | 0.68 |
| iPhone 14 Pro Max | CPU_AND_NE | SPLIT_EINSUM | 77* | 0.83 |
| iPhone 15 Pro Max | CPU_AND_NE | SPLIT_EINSUM | 31 | 0.85 |
| iPad Pro (M1) | CPU_AND_NE | SPLIT_EINSUM | 36 | 0.69 |
| iPad Pro (M2) | CPU_AND_NE | SPLIT_EINSUM | 27 | 0.98 |
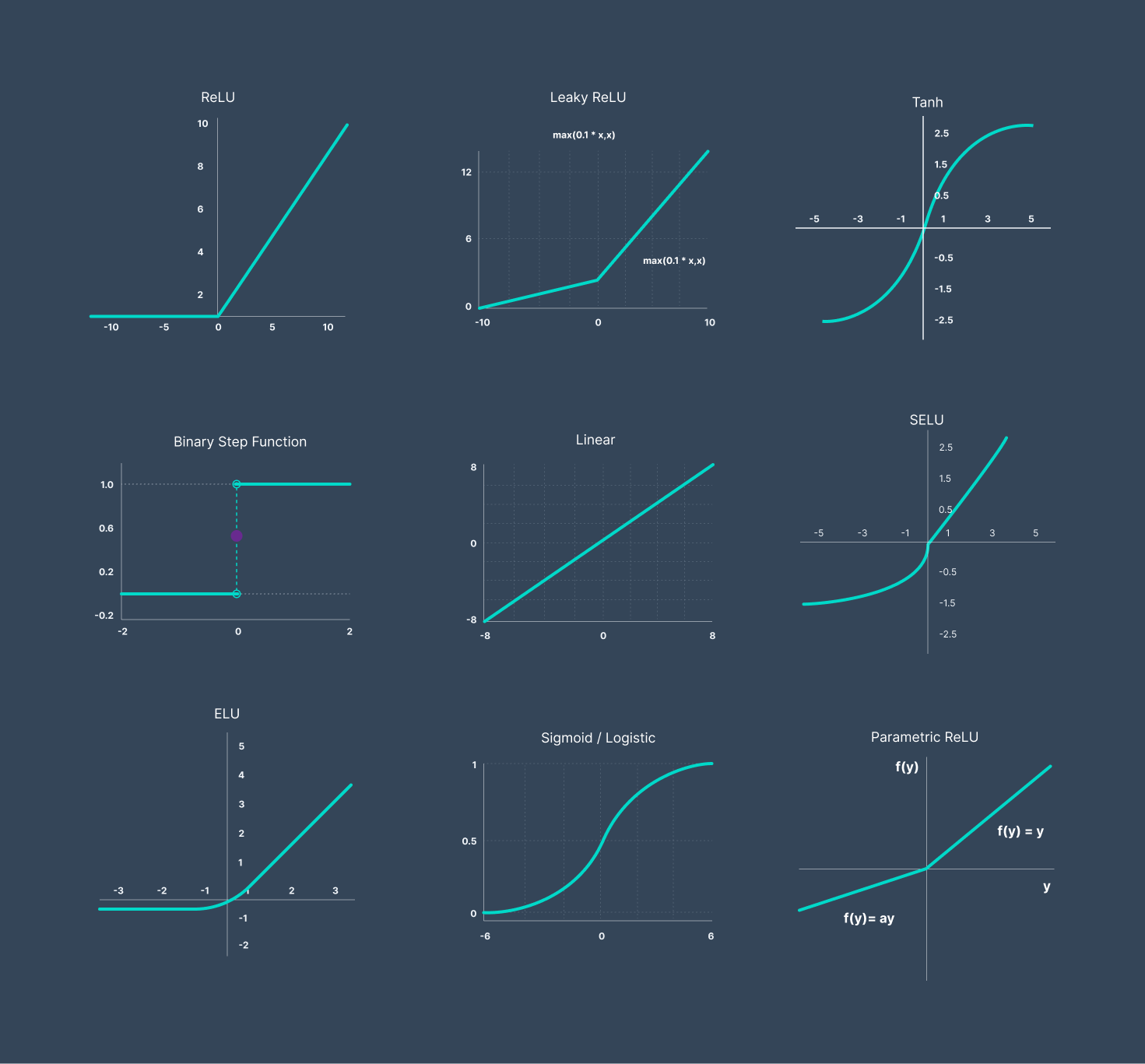
What makes inference not just trivial linear algebra is that after each linear step (eg a convolution of matrix multiplication) there is non-linear step that maps the result through a non-linear function. Simplest of these is ReLU, but many different options exist, some "biologically inspired", some based on a hypothesis or other.What do you mean by activations? Are you referring to its usage in ML or something else?
Look at volume 7 of my PDFs atI’d love to have a look at those NPU-related patents if you have the links handy.
 github.com
github.com
I don't know what you are saying here.The original discrepancy was/is between the M3 number Apple used, and the A17 number. This flew in the face of everything that had come before, from the introduction of the ANE in 2017, and then A12/A12X+; A14/M1+; and A15/M2+ -- each of those generations had the same ANE in the base iPhone and the iPad/Mac variants.
The initial assumption was that it must be what you're saying here, Apple's marketing being forced to keep up with the Joneses, so to speak. Look at how Qualcomm presents this here, explaining the math (which is beyond me):

A guide to AI TOPS and NPU performance metrics
TOPS is a measurement of the potential peak AI inferencing performance based on the architecture and frequency required of the NPU.www.qualcomm.com
"The current industry standard for measuring AI inference in TOPS is at INT8 precision."
So Apple had to start doing that. Simple enough. We know that they used FP16 in the past, they say it explicitly here:
Deploying Transformers on the Apple Neural Engine
An increasing number of the machine learning (ML) models we build at Apple each year are either partly or fully adopting the Transformer…machinelearning.apple.com
I'm sorry to say, however, that I may have been the one to introduce the idea of "support" for INT8. This was based on something Ryan Smith said in Anandtech re: the A17/M3 discrepancy in 2023: "The question is [...] whether the NPU in the M3 even supports INT8, given that it was just recently added for the A17. Either it does support INT8, in which case Apple is struggling with consistent messaging here, or it’s an older generation of the NPU architecture that lacks INT8 support."
But you'll notice that in his more recent mention of it, with regard to M4, he does not use the word "support" while saying, "freely mixing precisions, or even just not disclosing them, is headache-inducing to say the least" ... His failure to mention the question of architectural "support" for the lower 8-bit precision would seem to align with your argument, that it's not a thing, or at least that there's no evidence that it is a thing.
2023 M3: https://www.anandtech.com/show/2111...-family-m3-m3-pro-and-m3-max-make-their-marks
2024 M4: https://www.anandtech.com/show/21387/apple-announces-m4-soc-latest-and-greatest-starts-on-ipad-pro
If folks are still interested apple own diffusion repo with highly optimized options provide results for already compressed models it seems like A17 and A15 isn't much different. (last column iter/sec).
So it seems that they indeed just change F16 to I8 for TOPS calculation as most NPU providers are doing atm.
iPhone 12 Pro CPU_AND_NE SPLIT_EINSUM 116* 0.50 iPhone 13 Pro Max CPU_AND_NE SPLIT_EINSUM 86* 0.68 iPhone 14 Pro Max CPU_AND_NE SPLIT_EINSUM 77* 0.83 iPhone 15 Pro Max CPU_AND_NE SPLIT_EINSUM 31 0.85 iPad Pro (M1) CPU_AND_NE SPLIT_EINSUM 36 0.69 iPad Pro (M2) CPU_AND_NE SPLIT_EINSUM 27 0.98
By me, I gather you mean Ryan Smith at Anandtech? I’m just the messenger. Are you saying Apple did not “freely mix precisions” (to paraphrase Smith) in the starkly different TOPS numbers cited for A17 (and now M4) versus M3?I don't know what you are saying here.
We know how the ANE arithmetic unit works (takes in FP16 or INT8 [or a combination of the two]), multiplies, and accumulates to FP32 or INT32. I couldn't be bothered to look up the patent here, but it's one of the first ANE patents, and is mentioned in my volume 7.
It's not hypothesis that INT8 exists, and it's not true that it was in any sense recently added. There are multiple lines of evidence, from the patent trail to performance data, to CoreML APIs.
Apple are always reluctant to say anything even slightly technical about their hardware, not least because idiots then use the slightest technical mis-statement as an excuse for a lawsuit. So I wouldn't spend too much effort on the sort of parsing you're engaged in.
With the ANE it's even more complex than with other NPUs because ANE supports mixed precision, namely one of the inputs to the FMAC can be FP16 while the other is INT8 (that's one reason they have a patent).
So do you count this as an INT8 OP or an FP16 OP? You can see how stupid this counting becomes (even before the fact that, as just mentioned above, and as I have pointed out multiple times, TOPS count has little correlation with exhibited inference performance).
I simply could not parse the set of sentences you provided to reach any sort of conclusion. Maybe that's because Ryan had nothing explicit to say? Or perhaps you were trying so hard to distance yourself from what Ryan was saying that the resultant levels of indirection became impenetrable?By me, I gather you mean Ryan Smith at Anandtech? I’m just the messenger. Are you saying Apple did not “freely mix precisions” (to paraphrase Smith) in the starkly different TOPS numbers cited for A17 (and now M4) versus M3?

By me, I gather you mean Ryan Smith at Anandtech? I’m just the messenger. Are you saying Apple did not “freely mix precisions” (to paraphrase Smith) in the starkly different TOPS numbers cited for A17 (and now M4) versus M3?
You can see in that earnings call that TSMC can't talk about their progress in advanced packaging without leaking their customers' plans, so they just ignore and/or deflect specific questions about it. One person asks about silicon interposers (pp. 12-13, the CEO's answer is "I'm not going to share with you because this is related to my customers' demand."), . . .
Well, all right. . . . You know the CoWoS-R, CoWoS-S, CoWoS-L, blah, blah, blah. All these kind of thing is because of our customers' requirement. . . . - C.C. Wei - TSMC CEO
I wonder, have you (people of this thread) come to any conclusions on why the “cadence” was lost and we got a m3max with RT last year but not an ultra. Why the m4 is parallel to the m3 and what the rumors for high end chips for studio and mac pro is and hand and plausible timeline? I really hope for a ultra (or better) desktop solution this fall but is that even in the cards?
Just to be clear — it wasn’t rhetorical, it was a genuine question. I’m still confused — is the A17 Pro NPU twice as fast as the M3 NPU or not? I guess there’s something fundamental about the question that I don’t understand, because the answers I’m getting don’t make sense to me.There is no evidence that Apple NPU has different performance for different data types. There is at least some evidence that it has the same performance for both INT8 and FP16. I think a lot of the conversation here is going in circles…
It seems it is in INT8 (or just they change how they calculate TOPS to I8 from F16) in every apple repo with they custom implementations for opensource ML models the difference seems to be minimal so M3 -> A17 seems like just TOPS over Flops difference.Just to be clear — it wasn’t rhetorical, it was a genuine question. I’m still confused — is the A17 Pro NPU twice as fast as the M3 NPU or not? I guess there’s something fundamental about the question that I don’t understand, because the answers I’m getting don’t make sense to me.
Just to be clear — it wasn’t rhetorical, it was a genuine question. I’m still confused — is the A17 Pro NPU twice as fast as the M3 NPU or not? I guess there’s something fundamental about the question that I don’t understand, because the answers I’m getting don’t make sense to me.
It seems it is in INT8 (or just they change how they calculate TOPS to I8 from F16) in every apple repo with they custom implementations for opensource ML models the difference seems to be minimal so M3 -> A17 seems like just TOPS over Flops difference.
I argue that the A17 chip is slightly faster, so they or they could modify the performance calculation method (e.g., TOPs vs. FLOPS, and I8 was always twice as fast as F16?). However, I lack the ability to test this claim in low-level code because there’s no public API that provides access to any low-level NPU calls, and exporting I8 and F16 consistently yields almost the same performance on Mac (M1 and M2) and nowhere near twice the performance.According to the currently available benchmarks and tests the A17 NPU is only marginally faster, if at all.
I don’t understand this. If you want to make an argument like that you‘d need to demonstrate actual performance difference at various precisions. Why do you expect INT8 to be any faster than FP16?
I argue that the A17 chip is slightly faster, so they or they could modify the performance calculation method (e.g., TOPs vs. FLOPS, and I8 was always twice as fast as F16?). However, I lack the ability to test this claim in low-level code because there’s no public API that provides access to any low-level NPU calls, and exporting I8 and F16 consistently yields almost the same performance on Mac (M1 and M2) and nowhere near twice the performance.
Furthermore, it’s possible that this performance difference is due to software limitations rather than a hardware. Additionally, I don’t have access to an M4 or an A17 device to test any of these claims on the latest beta.
As i wrote before i don't argue just speculation as APPLE IS SAYING they double the speed of NPU not me man xDOk, in other words all evidence you have suggests that I8 and FP16 run at the same speed. What reason do you have then to argue that they are different?
As i wrote before i don't argue just speculation as APPLE IS SAYING they double the speed of NPU not me man xD
The most recent patent you cite is from 2022, no?Look at volume 7 of my PDFs at

GitHub - name99-org/AArch64-Explore
Contribute to name99-org/AArch64-Explore development by creating an account on GitHub.
I know about ML, but nice explanation for others 👍What makes inference not just trivial linear algebra is that after each linear step (eg a convolution of matrix multiplication) there is non-linear step that maps the result through a non-linear function. Simplest of these is ReLU, but many different options exist, some "biologically inspired", some based on a hypothesis or other.
These non-linear lookups are frequently called activations.
ReLU is trivial to implement in hardware. Some of the other activation functions are (if you implement the exact spec) fairly expensive. It's unclear what Apple does, especially on ANE. Certainly in early versions of ANE, ReLU was cheap and implemented in multiple places (so that whatever the previous step was - convolution, pooling, normalization, whatever, it was free to just add a ReLU after that if required).
The Apple Foundation Models for Language use a fairly complex activation function, SiLU (I believe this is biologically inspired) so I suspect that ANE has been upgraded to handle more generic activation functions (maybe something like hardware where you program ten points into a table and the hardware does a linear interpolation based on those ten points?) but probably still able to give you a "free" activation after every "serious" layer type.
(BTW what activation is optimal where is still an unsolved, not even really an understood, problem. Like so much in neural nets there's a massive amount of optimization still waiting to be applied even to fairly old networks, to truly understand what matters vs what computation can be simplified.)
Attempts to go beyond this (ie to train an already trained model on a large quantity of something new) result in catastrophic forgetting of the old material and (as far as I know) there is no robust way of "locking in" or "segregating" the earlier material to achieve something fairly reliably like how a human learns year after year.
So the question is: can you engage in continual modification of LoRA layers to achieve lightweight ongoing learning
The GPU binning, as I said before, was likely as much a matter of market segmentation as of recovering chips due to defects. Although I think (I am not sure) that the GPU "cores" are rather larger than CPU P cores, so binning for a failure in one of them is more practically useful compared to binning for a defect in a single P core (as it recovers more chips that would otherwise be scrap).They've done GPU binning on iPhone-grade silicon before with the A15. The Pro model had 1 more GPU core (5 vs. 4) than the A15 in the regular phone. What would them doing different mask sets mean for the Pro chip, that they have bigger plans for it? When the M3 Pro went for a more density optimized design, that enabled them to go bigger with the M3 Max.
If you can find later patents, by all means share.The most recent patent you cite is from 2022, no?
The GPU binning, as I said before, was likely as much a matter of market segmentation as of recovering chips due to defects. Although I think (I am not sure) that the GPU "cores" are rather larger than CPU P cores, so binning for a failure in one of them is more practically useful compared to binning for a defect in a single P core (as it recovers more chips that would otherwise be scrap).
As discussed a month or two ago, "failure" includes "runs too hot"/"leaks too much", not just "doesn't work at all".If I recall correctly, it has been speculated that these chips were discarded based on power consumption (and of course market segmentation) rather than defects. As you rightly pointed out, it’s highly unlikely that a defect would fall on a GPU core.
