From Vega whitepaper:
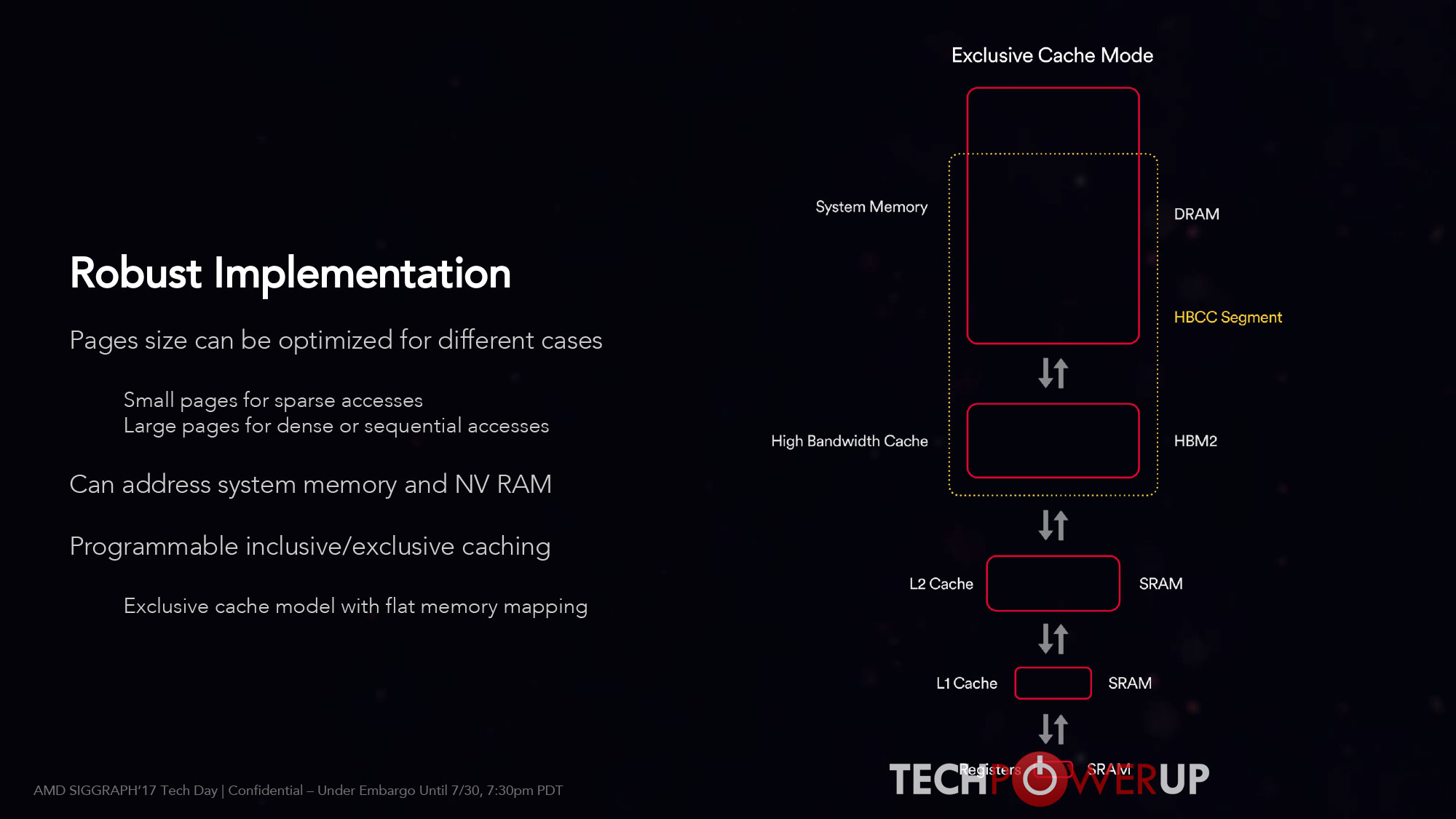
HBCC technology can be leveraged for consumer applications, as well. The key limitation in that space is that most systems won’t have the benefit of large amounts of system memory (i.e., greater than 32 GB) or solid-state storage on the graphics card. In this case, HBCC effectively extends the local video memory to include a portion of system memory. Applications will see this storage capacity as one large memory space. If they try to access data not currently stored in the local high-bandwidth memory, the HBCC can cache the pages on demand, while less recently used pages are swapped back into system memory. This unified memory pool is known as the HBCC Memory Segment (HMS).
Intelligent Workload Distrubutor is "aware" of the data that is not stored in on-GPU cache, and can access it instantly.
Everything depends on implementation, and instructions in software. HBCC indexes not only the data that is stored in GPU memory. It indexes RAM, Non-volatile storage, even CPU page tables.

That is why HBCC can help in increasing gaming performance. Because the GPU this way can avoid stalls, and fill the cores, with work.
Funniest part. As always on this forum, you are arguing with me about the same thing, but looking from two different angles.
As for Intelligent Workload Distributor, this slide is very helpful in understanding why features have to be perfectly synced to extract everything out of Vega:

HBCC technology can be leveraged for consumer applications, as well. The key limitation in that space is that most systems won’t have the benefit of large amounts of system memory (i.e., greater than 32 GB) or solid-state storage on the graphics card. In this case, HBCC effectively extends the local video memory to include a portion of system memory. Applications will see this storage capacity as one large memory space. If they try to access data not currently stored in the local high-bandwidth memory, the HBCC can cache the pages on demand, while less recently used pages are swapped back into system memory. This unified memory pool is known as the HBCC Memory Segment (HMS).
Intelligent Workload Distrubutor is "aware" of the data that is not stored in on-GPU cache, and can access it instantly.
Everything depends on implementation, and instructions in software. HBCC indexes not only the data that is stored in GPU memory. It indexes RAM, Non-volatile storage, even CPU page tables.
That is why HBCC can help in increasing gaming performance. Because the GPU this way can avoid stalls, and fill the cores, with work.
Funniest part. As always on this forum, you are arguing with me about the same thing, but looking from two different angles.
As for Intelligent Workload Distributor, this slide is very helpful in understanding why features have to be perfectly synced to extract everything out of Vega:

