Got a tip for us?
Let us know
Become a MacRumors Supporter for $50/year with no ads, ability to filter front page stories, and private forums.
Will there be a new Mac Pro in 2015?
- Thread starter Anto38x
- Start date
- Sort by reaction score
You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
- Status
- Not open for further replies.
This isn't possible for first generation HBM. Looking at pictures of Fiji, it may be possible to fit another stack on both sides of the die, giving 6 GB of HBM.
You don't add another stack. You stack the dies higher. 8-Hi is technically possible in HBM1
http://www.fudzilla.com/news/memory/37308-hbm-1-memory-of-amd-fiji-pictured
It isn't very affordable. I don't think it is a linear increase in cost because the complexity is higher also. HBM2 increases in density means can have more memory in a shorter stack ( or just as "short" at 4-Hi).
There is only one 'consumer' of HBM1 now ( so fewer HBM 4-Hi buy the discounts aren't as good) and a substantially more expensive card isn't going to make much headway with Fiji.
It makes far more sense for AMD to work on asynchronous/concurrent main memory to HBM data tranfers using the "extra" bandwidth they have that the current cores can't use. That is a better spend than on super expensive RAM variant.
FUDZilla is not the best site to get your knowledge ")
So in their mind 16 Gb is equal to 2 GB, and 32 Gb is equal to 8?
Each chip has 256 MB, which goes for 1 GB stacks that have 128 GB/s bandwidth. There are four stacks for which in total goes for 4GB and 512GB/s. AMD theorized that its possible to link by the same lines two stacks, which would lead for 8GB in total but with the same bandwidth. I have not heard that it would be possible to get 8 GB from first implementation of HBM, apart from that Dual linking in the die itself.
In addition, 4-Hi HBM1 16Gb (2GB per chip) and 8-Hi HBM1 32Gb (8GB per chip) is possible and HBM2 will get double the bandwidth and density.
So in their mind 16 Gb is equal to 2 GB, and 32 Gb is equal to 8?
Each chip has 256 MB, which goes for 1 GB stacks that have 128 GB/s bandwidth. There are four stacks for which in total goes for 4GB and 512GB/s. AMD theorized that its possible to link by the same lines two stacks, which would lead for 8GB in total but with the same bandwidth. I have not heard that it would be possible to get 8 GB from first implementation of HBM, apart from that Dual linking in the die itself.
Would the additional memory require a change to Fiji, as in some modifications to the memory controller on the die to address the additional memory? If it were possible, AMD could come out with a professional version of the card which typically have >= 8 GB of memory and a significant cost increase. Otherwise, AMD tends not to release variants of the same architecture.You don't add another stack. You stack the dies higher. 8-Hi is technically possible in HBM1
http://www.fudzilla.com/news/memory/37308-hbm-1-memory-of-amd-fiji-pictured
It isn't very affordable. I don't think it is a linear increase in cost because the complexity is higher also. HBM2 increases in density means can have more memory in a shorter stack ( or just as "short" at 4-Hi).
There is only one 'consumer' of HBM1 now ( so fewer HBM 4-Hi buy the discounts aren't as good) and a substantially more expensive card isn't going to make much headway with Fiji.
It makes far more sense for AMD to work on asynchronous/concurrent main memory to HBM data tranfers using the "extra" bandwidth they have that the current cores can't use. That is a better spend than on super expensive RAM variant.

There's a lot of speculation regarding 8GB in HBM1. Theoretically it should be possible, but most people set you the dogs if you say so.
Still, in case it is, I'm not sure it would change the interposer size at all. It should rise in height on the existing mem and not adding additional chips to the interposer. Correct me if I'm wrong though.
What would happen is an increase in height of the whole package, which could provide an additional challenge in cooling, efficient cooling that is. As it is, GPU and mem have different heights already, and thermal compound is used to correct this, but a lot of it usually is bad for thermal conductivity. If you add more of it, worse it gets.
On another note, anyone find news on El Cap beta 3?
Still, in case it is, I'm not sure it would change the interposer size at all. It should rise in height on the existing mem and not adding additional chips to the interposer. Correct me if I'm wrong though.
What would happen is an increase in height of the whole package, which could provide an additional challenge in cooling, efficient cooling that is. As it is, GPU and mem have different heights already, and thermal compound is used to correct this, but a lot of it usually is bad for thermal conductivity. If you add more of it, worse it gets.
On another note, anyone find news on El Cap beta 3?
I have more questions and observation about the potential of Fury to make it in a nMP, if anyone has one or read more tests than I did:
- Can it drive 3 5k displays? What about 4k displays? AMD says it has Eyefinity and can support 6 displays, without specifying the resolution.
- Could a R390 class GPU, which can go to 8GB be superior to a Fury in terms of OpenCL compute perf? The memory bandwidth of the Fury is 512GB/s whereas that of the R390 is 384GB/s.
I ask that last question because right now the D500s have 3GB of RAM and the D700s have 6GB. I can see Apple tailoring an hypothetical Fury-based D510 to 3GB (or 4GB), but I have a hard time seeing them going from a 6GB D700 down to a 4GB D710. They would need a black-hole class reality distortion field from marketing.
- Would it make sense in term of performance and market segmentation to make a D510 with Fury @ 3GB, discontinue the D700 and replace it with a D610 with Fury at 4GB? And say "we'll release a D700 / D800 class in 6 month with HBM2".
- Can it drive 3 5k displays? What about 4k displays? AMD says it has Eyefinity and can support 6 displays, without specifying the resolution.
- Could a R390 class GPU, which can go to 8GB be superior to a Fury in terms of OpenCL compute perf? The memory bandwidth of the Fury is 512GB/s whereas that of the R390 is 384GB/s.
I ask that last question because right now the D500s have 3GB of RAM and the D700s have 6GB. I can see Apple tailoring an hypothetical Fury-based D510 to 3GB (or 4GB), but I have a hard time seeing them going from a 6GB D700 down to a 4GB D710. They would need a black-hole class reality distortion field from marketing.
- Would it make sense in term of performance and market segmentation to make a D510 with Fury @ 3GB, discontinue the D700 and replace it with a D610 with Fury at 4GB? And say "we'll release a D700 / D800 class in 6 month with HBM2".
It turns out that post may be wrong. BIOS in Fury X says the TDP for that card is 275W. So reducing it by 40% gets it to around... 175W. Exactly the same as Fury Nano. What staggers me is reducing TDP by 100W reduced the max clock by only 15 MHz. Also the power consumption is nearly ideally reflected in the effects, because even if Fury X has 275W at stock on average it draws 246W http://tpucdn.com/reviews/AMD/R9_Fury_X/images/power_average.gifRelevant to the discussion is this forum post here, where someone tries to limit the power consumption of a Fury X to potential Fury Nano limits and sees very little decrease in performance. The catch here is I don't see any great measures of power consumption, so who knows if limiting power through the graphics drivers is actually doing anything.
Peaks at 280W. It makes sense.
However, I think I know why AMD did not pushed Fiji GPUs even further. It is because I believe they are worried about VRMs on the GPU. They can get to 100 degrees at water cooling. And that can be a problem, even if they are designed to get to 150 degrees C. For those who don't know VRM's are Voltage Regulators. Now you can see why AMD blocked at first the ability to change voltage.
It turns out that post may be wrong. BIOS in Fury X says the TDP for that card is 275W. So reducing it by 40% gets it to around... 175W. Exactly the same as Fury Nano. What staggers me is reducing TDP by 100W reduced the max clock by only 15 MHz. Also the power consumption is nearly ideally reflected in the effects, because even if Fury X has 275W at stock on average it draws 246W http://tpucdn.com/reviews/AMD/R9_Fury_X/images/power_average.gif
Peaks at 280W. It makes sense.
However, I think I know why AMD did not pushed Fiji GPUs even further. It is because I believe they are worried about VRMs on the GPU. They can get to 100 degrees at water cooling. And that can be a problem, even if they are designed to get to 150 degrees C. For those who don't know VRM's are Voltage Regulators. Now you can see why AMD blocked at first the ability to change voltage.
Thank You. It takes a big man (or woman) to admit when they are wrong.
I think most people would agree that a card with VRMs at 100C is pretty much "OC'ed to Hell" and has no more headroom.
I tried to put an Air Cooled Fury in my cMP. Literally the largest heatsink I have ever seen on a GPU. Dwarfs a Titan or a 7970. Less then 1cm clearance in length to put in cMP. I am pretty sure that this single Fury has more cooling capacity then an entire nMP.
Instead of guess work and wishful thinking, we will soon be able to get exact numbers for what speeds get what power draw. When you see this behemouth you will understand why I predict that there will never be a Fury X or Fury in nMP. Apple has painted themselves into a corner. It is either going to be Mobil AMD GPUs, older AMD GPUs, or a modern & efficient Nvidia GPU. No other top tier AMD answers, not at 125 Watts per card.
Sapphire Tri-X or Asus Strix Fury?
http://tpucdn.com/reviews/ASUS/R9_Fury_Strix/images/power_average.gif
http://tpucdn.com/reviews/ASUS/R9_Fury_Strix/images/power_peak.gif
Worst case scenario.
If you took Sapphire then I know you took it deliberately to show that Fury is not efficient.
I would like to turn to what you've wrote about efficient and modern Nvidia GPU. Which one in your mind is efficient and modern? And which one is in El Capitan Beta drivers? Because from what have already been shown in this thread in El Cap beta there already are indictions of Fury in drivers. And none for Maxwell GPUs.
Also I could bring numbers from computerese.de and golem.de for Fury, but I suppose you HAVE TO be right. So, of you can go from now.
End for me.
http://tpucdn.com/reviews/ASUS/R9_Fury_Strix/images/power_average.gif
http://tpucdn.com/reviews/ASUS/R9_Fury_Strix/images/power_peak.gif
Worst case scenario.
If you took Sapphire then I know you took it deliberately to show that Fury is not efficient.
I would like to turn to what you've wrote about efficient and modern Nvidia GPU. Which one in your mind is efficient and modern? And which one is in El Capitan Beta drivers? Because from what have already been shown in this thread in El Cap beta there already are indictions of Fury in drivers. And none for Maxwell GPUs.
Also I could bring numbers from computerese.de and golem.de for Fury, but I suppose you HAVE TO be right. So, of you can go from now
.End for me.
Last edited:
...
There are other manufacturers out there that will happily sell you a powerful workstation.
Maybe you could even go Hackintosh, you obviously know your way around the hardware and firmware, make yourself a custom Pro machine.
...
I still wonder why Apple doesn't rebadge a couple of good workstations (say a Z640 and a Z840) and sell them as Apples. No need to support every option that HP has, but definitely include CUDA GPUs as options.
It would seem to make more sense to keep the people who can't use the MP6,1 in the Apple fold, rather than drive them to Windows, Linux or Hackintoshes.
I think there is a problem with most of gcn gpus, they consume too much power when having high clocks, 290x at 1100 mhz draws around 80-100 watts more than at stock 1 ghz, 35% power usage increase for 10% increase in clock.
Something is very wrong with gcn at high clocks.
At low clock they become pretty good but less performant.
Something is very wrong with gcn at high clocks.
At low clock they become pretty good but less performant.
displayator, if I recall correctly you can drive 3 4K displays, but not 5K. Or 6 TBD.
DP performance in older GPUs is better than that with Fiji. Probably Artic islands will see a DP increase again. Pascal will at least.
Fury can't get 3GB, only 4GB. Fact is, HBM is not currently cut out to have that mem size differentiation.
koyoot, and with higher temps comes higher leakage, don't forget.
I'm also curious regarding those numbers, but as stated before, power is relatively well controlled with down clocking, which is quite common for Apple, so that wouldn't be an argument at all. They would set the freq to whatever level was necessary to keep it under the power limit. Or they can balance the load of both GPUs, if the display GPU is not requiring so much power, the compute one could clock higher automatically. How does that sound? Don't think it will happen though. So much so that I believe they're working on using both GPUs or some sort of XFire.
I can certainly see a Nano or even Pico in nMP, but that will cause rupture in the lineup.
Hardly nVidia though, and mobile is doubtful. Antigua and Grenada seems reasonable.
Aiden, do you really see Apple rebranding anything? They're too proud of their own development. No way, that will never happen. Honestly, I see little advantage in it. They'd have to support additional hardware that they don't control, as well as have additional drivers to update regularly.
It might indeed keep some people aboard but would that be worth it for Apple? Guess not.
I see them more promptly developing a newer tower Mac Pro, like everyone here wishes them to, and that would be indeed awesome.
But will it happen anytime soon? Don't think so unfortunately.
DP performance in older GPUs is better than that with Fiji. Probably Artic islands will see a DP increase again. Pascal will at least.
Fury can't get 3GB, only 4GB. Fact is, HBM is not currently cut out to have that mem size differentiation.
koyoot, and with higher temps comes higher leakage, don't forget.
I'm also curious regarding those numbers, but as stated before, power is relatively well controlled with down clocking, which is quite common for Apple, so that wouldn't be an argument at all. They would set the freq to whatever level was necessary to keep it under the power limit. Or they can balance the load of both GPUs, if the display GPU is not requiring so much power, the compute one could clock higher automatically. How does that sound?
Don't think it will happen though. So much so that I believe they're working on using both GPUs or some sort of XFire.I can certainly see a Nano or even Pico in nMP, but that will cause rupture in the lineup.
Hardly nVidia though, and mobile is doubtful. Antigua and Grenada seems reasonable.
Aiden, do you really see Apple rebranding anything? They're too proud of their own development. No way, that will never happen. Honestly, I see little advantage in it. They'd have to support additional hardware that they don't control, as well as have additional drivers to update regularly.
It might indeed keep some people aboard but would that be worth it for Apple? Guess not.
I see them more promptly developing a newer tower Mac Pro, like everyone here wishes them to, and that would be indeed awesome.
But will it happen anytime soon? Don't think so unfortunately.
netkas, every architecture has it's own drawbacks I guess. GCN seems to be good up to a point in speed. Maybe with the FinFET nodes coming it will scale better.
Unfortunately AMD doesn't seem to have the money to invest in further R&D to come up with better solutions.
But Apple will be spending more in R&D I believe. In what products we'll see.
Unfortunately AMD doesn't seem to have the money to invest in further R&D to come up with better solutions.
But Apple will be spending more in R&D I believe. In what products we'll see.
Netkas, yes that is correct. However, the Memory is not OCed. And it brings massive differences to performance. Cores have to be fed from Bandwidth. Thats how GCN architecture gets higher performance. Not from clocks on core. Also its worth noting that GCN architecture peaks at 1200 MHz.
That is exact opposite for Maxwell GPUs. They fly with high clock. And consume ginormous amounts of power when dealing with anything serious.
http://www.tomshardware.com/reviews/nvidia-geforce-gtx-980-970-maxwell,3941-12.html
If you have BIOS cap on Maxwell GPU it will not exceed the power Cap thanks to downclocking, but it will be massively slower. Exact opposite for GCN cards.
Maxwell GPUs benefit from extremely high clocks on core. GCN benefits the most from massive Memory bandwidth.
http://techreport.com/news/27996/4gb-gtx-960s-trickle-into-retail-channels?post=893388#893388
And we already seen other proofs of how well GCN architecture works in "underpowered" environment.
Manuel, yes I remember about the leakage, and to be honest it a little worries me. I guess however that
That is exact opposite for Maxwell GPUs. They fly with high clock. And consume ginormous amounts of power when dealing with anything serious.
http://www.tomshardware.com/reviews/nvidia-geforce-gtx-980-970-maxwell,3941-12.html
If you have BIOS cap on Maxwell GPU it will not exceed the power Cap thanks to downclocking, but it will be massively slower. Exact opposite for GCN cards.
Maxwell GPUs benefit from extremely high clocks on core. GCN benefits the most from massive Memory bandwidth.
One of the comments in:Power efficiency is an oft-used negative against the large-die Hawaii chips, but I've been playing with powertune settings and Furmark recently as an experiment to fit a "hot and noisy" AMD card into an SFF with limited cooling.
Actually, I stand by an earlier post I made that says I think AMD pushed Hawaii silicon too far.
With both GPU-Z and Furmark able to report power consumptions, I can see a 100W reduction in power consumption on 290X cards for as little as 5% performance loss.
If you have a Hawaii card, I urge you to crank power limits down in the overdrive tab of CCC and see what the resulting clockspeed is under full load. Even in a worst-case scenario, I'm seeing a typical clockspeed of 850MHz with the slider all the way to the left at -50%
That means that Hawaii (the two samples I personally own, at least) can run at 850+MHz on only 145W (half the 290W TDP). As mentioned, that's a worst-case scenario using a power-virus like Furmark. Under real gaming situations (I was messing around with Alien Isolation on 1440p ultra settings) the clocks averaged about 925MHz yet my PC was inaudible; Fans that normally hum along at 55% were barely spinning at 30% during my gameplay.
As Nvidia has proved, you can make a 28nm chip run efficiently. I think the design of Hawaii holds up very well under vastly reduced power constraints - AMD just pushed it outside its comfort zone in order to get the most out of it.
In saying that, the "underpowered" 290X is around the same performance as my GTX970 and also the same cost - significantly higher than a GTX960 4GB. I don't know if die-harvested 290 cards deal with power limit caps like the cherry-picked 290X cards.
http://techreport.com/news/27996/4gb-gtx-960s-trickle-into-retail-channels?post=893388#893388
And we already seen other proofs of how well GCN architecture works in "underpowered" environment.
Manuel, yes I remember about the leakage, and to be honest it a little worries me. I guess however that
Last edited:
However, the Memory is not OCed. And it brings massive differences to performance.
Enough with the unsupported FUD. You keep saying this but when you linked to an article it said the opposite.
Here is another one that got same lackluster results.
http://www.hardware.fr/articles/937-26/overclocking-gpu-fiji.html
Their conclusion:
"The same overclocking 8% of the HBM memory causes a performance increase of 0.8 and 4.6%, with an average of 2.5%. Its impact is therefore less in practice than overclocking the GPU." (Translated by Chrome)
So two different tech sites tried it, came to the same conclusion, but sitting in your chair without a Fury to be seen you know better then them?
And you also know better then Asus how much power their card uses.
Amazing, wish I knew everything too.
There is no magic to put this power hog in a nMP and keep anything resembling same performance. The Asus card you seem to glorify has a massive heatsink. You might ask yourself why.
but definitely include CUDA GPUs as options.
they won't.
gpgpu is still in it's infancy.. according to nmp design, apple is definitely envisioning large processing tasks to happen on the gpus instead of a bunch of cpu cores.
i'm pretty sure apple imagining a sort of software revolution in that any applications which greatly benefit from multiple processors will re-write to gpgpu for substantial performance gains.. in 5 years, a renderer which doesn't have (at the very least) gpu assist is going to be out of business.. they simply won't be able to compete.
anyway.. apple can't have these apps being re-written with cuda.. if they do, nvidia will have them by the balls with way too much negotiation power.. right now, apple doesn't support cuda and it's not a big deal.. in 5 years, if apple were to allow cuda apps to be written for mac-- and time came for apple/nvidia to renegotiate.. apple would pretty much have to agree to whatever deal nvidia wants because by then, it will be too late for apple to have the upper hand in the contracts.. pro applications on osx would require cuda and would require nvidia to be in the machines.
---
edit--
and really, you all love to paint nvidia/cuda as the victim here and apple as the bad guys.. nvidia is being just as wack or worse so with the proprietary language.. screw them too, you know?
----
you mean people that can't use apple because of cuda?It would seem to make more sense to keep the people who can't use the MP6,1 in the Apple fold, rather than drive them to Windows, Linux or Hackintoshes.
all 6 of them?
probably not a big deal to drive them away
..trying to keep those 6 people happy would result in much more serious losses down the line.
Last edited:
anyway.. apple can't have these apps being re-written with cuda..
You've not seen the benchmarks showing the GTX 980 beating AMD at OpenCL?
Rebranding would let Apple offer the fastest OpenCL systems as well as the fastest CUDA systems as well as the fastest x64 systems. (Here "fastest" is fuzzy - it will be as fast as other systems built with the same components - not significantly faster, but not significantly slower.)
It's win-win. Apple gets to add all of the CUDA apps - as well as keeping all of the OpenCL apps. Talking about rewriting OpenCL apps for CUDA is nonsense when Nvidia cards are faster at OpenCL than AMD cards.
Nvidia is taking OpenCL seriously - and seriously improving their newest GPUs to perform well. "Rewriting OpenCL apps" for CUDA is nonsense, and Nvidia knows that. Nvidia wants CUDA plus OpenCL - but they want to be at the top of OpenCL benchmarks and yet have CUDA beat OpenCL.
This is one of the most ignorant statements that I've seen on MacRumours, and I've been here for more than 15 years.you mean people that can't use apple because of cuda?
all 6 of them?
probably not a big deal to drive them away
Most GPGPU programs are CUDA-based. OpenCL dominates the wedding-video-editing market. CUDA is the only game in town for high end GPGPU programming. (I'm not high end, My top system only has 9216 CUDA cores (but I have several of those systems)).
Step out of your reality distortion field and look at what is happening in the real world on small systems with +25K CUDA cores. http://info.nvidianews.com/index.php/email/emailWebview?mkt_tok=3RkMMJWWfF9wsRolvavJZKXonjHpfsX57ekrXaayhYkz2EFye+LIHETpodcMScNgPa+TFAwTG5toziV8R7HAKs1v3NsQXBXg
Look for AMD GPUs on the Top500 Supercomputer list. And look....
i'm talking about rewriting cpu intensive applications into gpu intensive apps.Talking about rewriting OpenCL apps for CUDA is nonsense
as in- most apps which could see significant performance enhancements via gpgpu aren't currently coded to exploit all of the gpu cores.. apple wants these apps to be rewritten with openCL instead of cuda.
----
likewise, how about you step out of yours.. maybe you can post some stuff about the magical world of cuda that's not an nvidia advertisementStep out of your reality distortion field and look at what is happening in the real world on small systems with +25K CUDA cores. http://info.nvidianews.com/index.php/email/emailWebview?mkt_tok=3RkMMJWWfF9wsRolvavJZKXonjHpfsX57ekrXaayhYkz2EFye+LIHETpodcMScNgPa+TFAwTG5toziV8R7HAKs1v3NsQXBXg
or better yet, post up some examples of how you yourself are using cuda to your advantage in your workflow.
Aiden, do you really see Apple rebranding anything? They're too proud of their own development.
Pride - one of the seven deadly sins.
Apple isn't too proud to fill their data centers with HP ProLiant servers - even the Jobs showed a picture of row after row of HP servers during a keynote.
For Apple to rebrand a couple of HP workstations with a limited set of options is far different from saying that "we support Apple OSX on the Z640 and Z840".
If you can't buy it from Apple, don't expect support. Of course, that's irrelevant for video cards - since Nvidia will independently put out drivers for everthing that's even remotely current.
And since few serious GPGPU developers would choose a system with an AMD GPU.
to be honest @AidenShaw ,i don't think you even know what cuda is.. or what 'cuda cores' are.
and i certainly don't understand why it's seemingly so important to you..
it's like you're arguing "what's better.. python or ruby?"
...
then let's just say python is intel's proprietary language so they advertise "our processors contain python cores".. (sounds pretty cool i guess)
"cuda cores" is a marketing ploy by nvidia and it's done a number on you ; )
amd has 'cuda cores' too.. just like nvidia.. the only difference is that nvidia won't let you run cuda on amd processors.
and i certainly don't understand why it's seemingly so important to you..
it's like you're arguing "what's better.. python or ruby?"
...
then let's just say python is intel's proprietary language so they advertise "our processors contain python cores".. (sounds pretty cool i guess)
"cuda cores" is a marketing ploy by nvidia and it's done a number on you ; )
amd has 'cuda cores' too.. just like nvidia.. the only difference is that nvidia won't let you run cuda on amd processors.
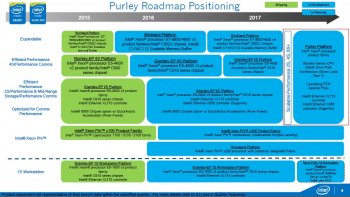
it's like you're arguing "what's better.. python or ruby?".
No, I'm asking for the having the choice between Python and Ruby.
The MP6,1 doesn't give you the option of choosing between GPGPU programming models.
it's nvidia that doesn't give you the choice.. not apple.No, I'm asking for the having the choice between Python and Ruby.
The MP6,1 doesn't give you the option of choosing between GPGPU programming models.
you get that, right?
Yes, I believe Apple is very proud of what they do. Sin or not, and I'm not going fanboy here, I do believe they make very good stuff, and even that they can/should be proud of it.
Some would say it's taken to extremes.
Mostly I believe it's just another sin, jealousy. They have success where others fall flat, and no one can understand why and how.
Still, their data centers must have loads of servers, and since Apple doesn't design/have/build servers in their lineup, they have no other choice as to use someone else's servers.
Should they spend a lot of money developing a server just to fill their server rooms? Should they also make it a commercially available product? Don't think Apple wants to get in that train.
Rebranding would be a problem, people would know for sure, and that would seems that Apple approves of Hackintoshes. And that, after all, Macs are only PCs with some kind of lock mechanism to keep people from running other stuff on them, which in fact is true, but some people don't know or care.
Guys, don't start another discussion please, we have enough of those here!! :-(
It's a hot topic yes, but keep it calm, we should all be having a cool exchange of ideas/thoughts on what the next MP should be, not starting wars on every page. Some might find it amusing though...
t0mat0, if they wait for Skylake it will be another 2 years before we see the nMP upgrade we're all looking forward to. SKL-EP is still too far off. It will be a great machine by then though
Some would say it's taken to extremes.
Mostly I believe it's just another sin, jealousy. They have success where others fall flat, and no one can understand why and how.
Still, their data centers must have loads of servers, and since Apple doesn't design/have/build servers in their lineup, they have no other choice as to use someone else's servers.
Should they spend a lot of money developing a server just to fill their server rooms? Should they also make it a commercially available product? Don't think Apple wants to get in that train.
Rebranding would be a problem, people would know for sure, and that would seems that Apple approves of Hackintoshes. And that, after all, Macs are only PCs with some kind of lock mechanism to keep people from running other stuff on them, which in fact is true, but some people don't know or care.
Guys, don't start another discussion please, we have enough of those here!! :-(
It's a hot topic yes, but keep it calm, we should all be having a cool exchange of ideas/thoughts on what the next MP should be, not starting wars on every page. Some might find it amusing though...
t0mat0, if they wait for Skylake it will be another 2 years before we see the nMP upgrade we're all looking forward to. SKL-EP is still too far off. It will be a great machine by then though
- Status
- Not open for further replies.
Register on MacRumors! This sidebar will go away, and you'll see fewer ads.