Tutor Says - Think differently when it comes to clocking newer processors.
...
If in all that stuff you posted you are suggesting that 16 2GHz cores will operate as fast or faster when operating with the same cores as the faster clocked, lower cored CPU then perhaps and that would be great, but I wouldn't count on it.
Exactly my suggestion which I've learned to count on daily for workstation apps, i.e., those multithreaded like Cinema 4d. As the lone wolf in the forest, I'm howling that we embrace a seeming paradox - a pack with many members moving slowly and methodically will seize the prey's entire clan faster than a small pack with greater speed. Underclocking a many-cored system, while positively biasing turbo boost ratios, yields greater speed advantages for less costs than simply goosing up the 24/7 speed of a few. This is in line with the methods I began employing of late and they are embraced fully within the Sandy Bridge E5 line to take advantage of inefficiencies in current processing and coding methods. Note that the result shown below comes from running dual W5680's in my MutliPro at
2.48 GHz and exaggerating their turbo ratios to amount to DDDDEE (or 13,13,13,13,14,14) [shown on every boot screen by verbosing (-v) to see native power management initialization]. I'd love to have 2, or even 4, more slow 2.48 GHz cores on each of my chips, not to mention better memory management.* (N.B. - Also the Geekbench 11.5 score in my sig resulting from this paradoxical clocking technique.) Cross pollination [mac -> hac -> mac -> hac ->mac ~] truly enriches us all.
* Here's some more stuff to chew on and fully digest - Lets do some math:
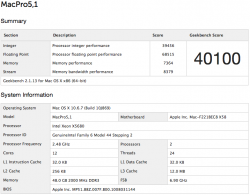
(1) Geekbench2 - If 40,100 is the yield from 6 cores, then 8cores/6cores [Sandy Bridge advantage] = 1.33 or 10cores/6cores [Ivy Bridge advantage] = 1.67; 1.33 x 40,100 = 53,333 or 1.67 x 40,100 = 66,967, assuming linearity and not accounting for better memory performance of Sandy [then later Ivy] Bridge, and
53,333 / 24,218 [
http://www.primatelabs.ca/geekbench/mac-benchmarks/#64bit] = 2.20 times faster than current top of the line, assuming linearity and not accounting for better memory performance of Sandy Bridge
66,967 / 24,218 [
http://www.primatelabs.ca/geekbench/mac-benchmarks/#64bit] = 2.76 times faster than current top of the line, assuming linearity and not accounting for better memory performance of Ivy Bridge
(2) Cinebench 11.5 (almost perfect proxy for Cinema 4d) - If 24.70 is the yield from 6 cores, then 8cores/6cores [Sandy Bridge advantage] = 1.33 or 10cores/6cores [Ivy Bridge advantage] = 1.67; 1.33 x 24.70 = 32.85 or 1.67 x 24.70 = 41.25, assuming linearity and not accounting for better memory performance of Sandy [then later Ivy] Bridge, and
32.85 / 15.45 [
http://www.cbscores.com/] = 2.13 times faster than current top of the line, assuming linearity and not accounting for better memory performance of Sandy Bridge
41.25 / 15.45 [
http://www.cbscores.com/] = 2.67 times faster than current top of the line, assuming linearity and not accounting for better memory performance of Ivy Bridge